Redis原理-源码解析:数据结构3 hash
Redis原理-源码解析:数据结构3 hash 所有原理实现基于Redis版本6.0.9 hash在Redis中可以认为是套了一层的string,当然,对hash来说没有数字类型 让我们依旧通过基本命令看看hash的基本数据结构实现 在set方法中我们看到了hash的初始创建过程,一个hash最开始是zipist 想要了解ziplist可以看Redis原理-源码解析:数据结构2 list ,是为节省内存而生的链表格式 所以其实在使用ziplist时其查询的时间复杂度不是遵循hash的近似O(1),而是O(n),但是在数据量不大时,这种性能的损失微乎其微,并且能预见到大多数使用hash的场景都不会存储过多的字段 所以优先使用了更节省内存空间的ziplist

2020-11-29鱼鱼
Java中的动态代理与静态代理
Java中的动态代理与静态代理proxy(代理)作为一种设计模式在Java中已经应用非常广泛,例如常见的拦截器是代理模式设计的,AOP是通过动态代理实现的,而基于AOP的应用就更多了,从简单的事务应用到Dubbo框架,Java开发中离不开代理,本篇文章主要阐述Java中的代理,此处是比较狭义的代理,仅指方法和类中的代理 代理模式是一种非常常见的设计模式,它通过给某对象提供代理,从而通过代理对象控制原对象的引用 以下是代理模式的简单实现: 类Admin: 对应的代理类AdminProxy: 设计良好的聚合代理模式应该是代理类与被代理类共同继承一个接口,此处只为实现功能 这样在执行new AdminProxy().changeWorld()时,除了会调用原本的new Admin().changeWorld(),在方法前后也可以做出些其他的操作
![Java中的动态代理与静态代理]()
2019-08-09鱼鱼
项目异常问题解决
项目异常问题解决这天 程序抛出了一个WARN日志: createSecureRandom Creation of SecureRandom instance for session ID generation using [SHA1PRNG] took [43,844] milliseconds. 这意味着SHA1PRNG算法导致项目启动多花费了43秒,这是基于SHA-1算法实现且保密性较强的伪随机数生成器 1.从tomcat层面上解决: 在catalina.sh中加入这么一行:-Djava.security.egd=file:/dev/./urandom 2.从java层面解决 打开$JAVA_PATH/jre/lib/security/java.security这个文件,将下面的内容:
2019-02-28鱼鱼
数据库的瓶颈问题解决(主从分离)与多数据源切换
数据库的瓶颈问题解决(主从分离)与多数据源切换业务中,数据库的设计是极为重要的一环,在高并发的业务中,我们可以采用集群部署来缓解请求和逻辑处理的压力,但是在数据库的层面却不行,Oracle、Mysql等数据库的吞吐量很高,但是依旧有阈值,我们不能奢求单库能解决所有的问题,假设遇到了数据库的瓶颈问题,我们可以采用怎样的手段呢 想要数据库达到瓶颈(SQL执行效率明显变慢),其实是很困难的,我们在程序的设计中基本都会使用到数据库连接池控制数据连接,但当业务量提升之后,连接池若是经常达到饱和便容易产生阻塞,我们不得不开放更多的连接数,随之而来的便是数据库承载了更多的并发,解决问题的主要方式有三: 更细的划分业务逻辑,将高频业务表单独分离开来,并通过定期清理的方式减小查询的执行时间,将不同的数据库请求分发到不同服务器的不同库,可以一定程度下解决上文所述的问题,但是应以数据库的设计性为前提,绝对不能牺牲原有设计合理的数据结构将其进行拆分,得不偿失

2019-08-29鱼鱼
算法:Trie(前缀树、字典树)
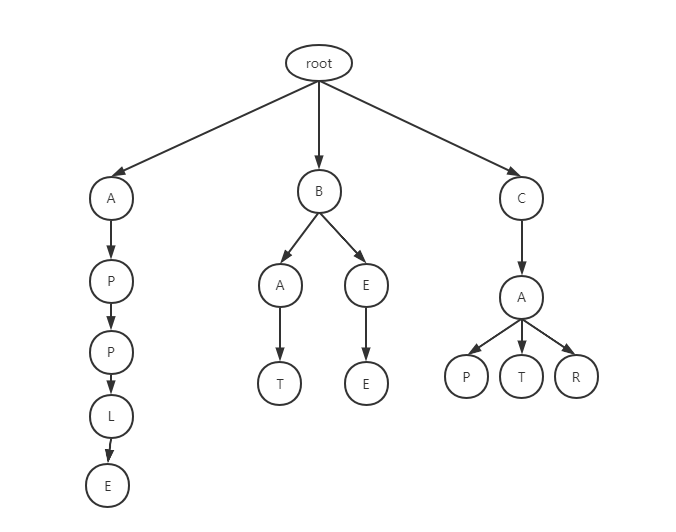
算法:Trie(前缀树、字典树)前缀树(Trie,又称字典树)是一种功能倾向性很强的数据结构,通过对词汇的前缀做数结构,很容易实现查询、前缀词推荐系统,例如,我们将如下多个单词放入树结构中: [apple,bat,bee,cat,cap,car],最终生成的前缀树结构为 通过深度递归,我们很容易用较小的时间复杂度判断出符合前缀的单词在不在 假设Trie的字符集范围是固定的,并且范围不大,例如是上面的纯英文字符,假设忽略大小写总共为26个,可以选择使用桶结构进行存储,即每一个Node都是一个长度为26的bucket数组 这样看来,Trie的结构并不复杂,只通过循环不断提高深度进行遍历即可 假定字符集的范围是未知的,或者范围很大(比如中文汉字),就要放弃使用bucket结构,而是通过一个Map维护,这里使用树结构TreeMap,key为相应节点的字符
2021-01-19鱼鱼
JVM源码解析 从Launcher类浅谈ClassLoader(类加载器及双亲委派)
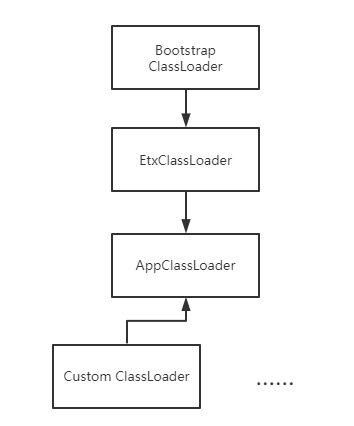
JVM源码解析 从Launcher类浅谈ClassLoader(类加载器及双亲委派)首先普及ClassLoader的基础:所有的Java类都是由ClassLoader由class文件加载进内存的,对于一个类,其唯一标识就是类名+加载他的ClassLoader(亦即对于不同的 ClassLoader,即使是加载了同一个Class也不能互通,本质上是两个类),其基本的分类如下图: BootstrapClassLoader是一个特殊的ClassLoader,负责启动时加载jre的类库 并不继承于ClassLoader,因为是jvm逻辑的一部分; ExtClassLoader也会加载jre类库,但是会加载那些额外的扩展类库(jre\lib\ext目录),到这个级别的 类加载器已经可以直接在代码中使用了;
2020-11-28鱼鱼
待办事宜
待办事宜2018-10-18 解决XSS攻击问题(v-html) 针对缺省有所设置(blog:page等) 添加新增按钮 添加置顶 解决日志编辑首行出现空格 开发射线:一个匿名交流板 留言 联系方式 可回复 筑楼 时限性 超时关闭 匿名 默认匿名 字典: 可标注,添加富文本新组件字典(视情况添加 工作量难以预估 可考量在全网) 字典包括 可见性(待定),条目,解释,相关词条 必须可编辑 添加不同风格 参照http://www.unconstraint.cn/,github两种风格可切换 流动 简约 重金属 使用图床存储较大的图片(RECOMMEND:使用新浪微博)
![待办事宜]()
2019-03-24鱼鱼
Spring源码解析(1) 基于SSM看Spring的使用和Spring启动监听
Spring源码解析(1) 基于SSM看Spring的使用和Spring启动监听查看源码的顺序就见仁见智了,比较普遍的做法是从IoC入手,了解容器注入的每一个环节,掌握大致的流程 由于使用的是Spring,所以在这里我们引入比较古老的xml配置文件进行bean的配置,首先定义一个bean: 配置描述bean的xml,核心只有一行: 这样一来就可以使用BeanFactory这个容器来注入bean并使用了: 本来有封装好的XmlBeanFactory,这一类现在已经被弃用了,所以采用了他的父类DefaultListableBeanFactory;当然,也可以使用更加方便和常用的ApplicationContext: 当然从xml文件读取bean的配置只是其中一种目前用的不多的加载方式,还有基于包扫描等加载bean的方法,此处仅为理解IoC的基本使用

2020-08-04鱼鱼
数据库的存储过程、触发器和一些语法
数据库的存储过程、触发器和一些语法本篇文章讲述基于MySQL的存储过程触发器和一些相关的语法 在数据库中,存储过程是指将复用度很高并且不需要通过程序进行预编译的的SQL语句预先写好存放起来(此处所指的为用户定义在数据库中的存储过程),在需要时直接通过call调用 先看一个例子(注意,这不是创建存储过程的语句): 其中使用了日期相关的函数,DATE_SUB(CURDATE(),INTERCAL 10 DAY)代表当前时间前推十天 这个存储过程作用是查出十天前的数据然后将其删除 MySQL默认的分隔符是" ; ",这样一来定义存储过程就会因为 ; 被打断,所以在定义存储过程前后需要修改分隔符,使用DELIMITER关键字跟随分隔符,实际创建存储过程语句为:
![数据库的存储过程、触发器和一些语法]()
2019-06-12鱼鱼
多线程应用提高(I) 多线程常见问题、常用方法和关键字
多线程应用提高(I) 多线程常见问题、常用方法和关键字我们一般熟识的创建多线程方式即为继承Thread类或是实现Runnable接口,重写run()方法,还有创建线程池实现 手动定义一个线程任务(作为内部类)的方法现在已经不被提倡,所以遇到可能存在并发的复杂任务时,一般采用线程池来实现 一些设计并发常用并且容易被混淆的方法们: static sleep() : Thread类的静态方法,阻塞当前正在线程,不释放锁; wait() : 当前线程暂停,并释放锁且暂时无法重新获得锁,必须绑定当前对象内容锁(如使用Synchronized的同步块),知道其他线程调用notify()/notifyAll()才有机会获得锁继续执行; yield() : 当前线程暂停,此时时间片分配给其他线程,但是不会分配给优先级更低的线程;
![多线程应用提高(I) 多线程常见问题、常用方法和关键字]()
2019-12-07鱼鱼
[Quick Start]使用RedisTemplate操作Redis
[Quick Start]使用RedisTemplate操作RedisRedisTemplate现在作为使用率最高的redis三方类库,隶属Spring技术栈,此篇文章意在指引RedisTemplate的快速上手 在实践前,请确保已经有一个可连接的Redis服务 Redis有五大基本数据类型:string、hash、list、set和zset string即是最单纯的k-v存储方式,使用set、get等指令 hash是哈希表的存储方式,比较适合用来存储对象,每一条value相当于Java的一个Map,使用hmset、hget等指令 list是简单的有序列表,每一条value相当于Java的一个List,使用lpush、lpop、rpush、rpop等指令
![[Quick Start]使用RedisTemplate操作Redis](/blog_cover/20200220/cdd943f261664778a1c746b93930db3a.png)
2020-02-23鱼鱼
关于多数据源的那些事儿(萌新向)
关于多数据源的那些事儿(萌新向)在日常的JAVA后端开发中多数据源的应用场景并不少见,但对于刚刚接触springboot或是刚刚接触工程化开发的萌新来说却仿佛是一座不可逾越的高山,因为新手常常会局限于某些“固定的”项目配置,不知道如何配置?从哪里开始配置?以及什么能改什么不能改 这种现象在用惯了springboot便捷开发的老手中也很常见,众所周知,相比于spring的springboot简化了很多工程前置配置,虽然增加了工作效率却也使得开发人员失去了了解基础配置的机会 综上,本文主要讲解如何在springboot环境中,以一种最简单的、即起即用的、不依赖中间件和数据库切片的方式配置单一项目的多数据源 限于笔者能力有限,经验尚浅,若有描述不当之处,敬请批评指正

2019-06-28Agostino
