阿里巴巴Java开发手册 华山版 v1.5
阿里巴巴Java开发手册 华山版 v1.5《Java 开发手册》是阿里巴巴集团技术团队的集体智慧结晶和经验总结,经历了多次大规模一线实战的检验及不断完善,公开到业界后,众多社区开发者踊跃参与,共同打磨完善,系统化地整理成册 现代软件行业的高速发展对开发者的综合素质要求越来越高,因为不仅是编程知识点,其它维度的知识点也会影响到软件的最终交付质量 比如:数据库的表结构和索引设计缺陷可能带来软件上的架构缺陷或性能风险;工程结构混乱导致后续维护艰难;没有鉴权的漏洞代码易被黑客攻击等等 所以本手册以 Java 开发者为中心视角,划分为编程规约、异常日志、单元测试、安全规约、MySQL 数据库、工程结构、设计规约七个维度,再根据内容特征,细分成若干二级子目录

2020-02-24鱼鱼
第一个Vue前端独立项目构建尝试(工程化)
第一个Vue前端独立项目构建尝试(工程化)开始我的第一个前端独立项目的构建 使用webPack、npm进行项目模块化构建 安装相关软件准备构建: VSCode npm(node) 查看版本 npm -v node -v 安装相关依赖(使用淘宝镜像): npm install -g cnpm --registry=http://registry.npm.taobao.org 安装vue-cli脚手架: npm install -g vue-cli 查看版本: vue --version 进入目录后新建vue工程: vue init webpack projectname 配置相关内容:

2019-05-04鱼鱼
并发之AQS全解析
并发之AQS全解析我们知道juc(java.util.concurrent)包下有很多实用的类,提供了很多并发工具,例如线程池、原子类、并发工具、信号量工具、锁等,可以说基本实现都为悲观锁,底层原理基本都使用了AQS(AbstractQueuedSynchronizer),AQS不是一种概念,是并发中实打实的工具类 本篇文章针对AQS做解析 AQS是多线程访问共享资源的同步器框架 AQS的资源可以是独占的也可以是共享的 我们先来简单看一下它的使用方式和ApI(因为是抽象类,是不能直接使用的),下图是AQS的整体脉络 AQS核心就是一个状态值state,同时维护了一个线程的阻塞队列,队列的节点为有两种状态:SHARED(共享)和EXCLUSIVE(独占),节点状态有五种:
![并发之AQS全解析]()
2021-03-12鱼鱼
JVM的垃圾回收
JVM的垃圾回收此文介绍Java的基本垃圾回收机制 GC主要回收的是堆区,在堆中是有对象分代的,一个对象每“逃”过一次回收,对象代数便+1,新生对象被称作新生代(如果是占据内存较大的对象直接定义为老年代),当代数一定时对象将由新生代变为老年代 同时在Java1.7之前还有永久代,保存了一些静态变量 总之,内存回收只发生在新生代和老年代之间 除了分代,内存也有分区: 如图,是内存区域分配,其中Eden存储了新建的小对象,当回收时,将Eden中存活的对象转移到To Survivor区中,将From Survivor中的代数高(一般是15)的存活对象转移到老年代中,代数没达到阈值的存活对象转移到To Survivor中
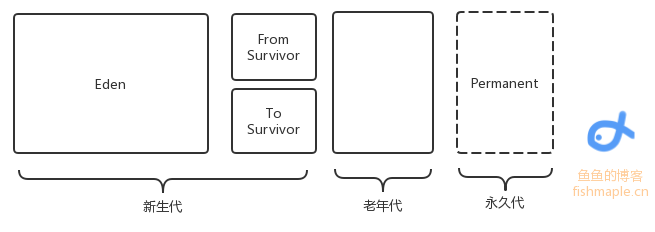
2021-04-07鱼鱼
Java的socket通信
Java的socket通信网络编程中,会使用socket通信 TCP/IP协议,即Transmission Control Protocol/Internet Protocol,传输控制协议/网际协议,他使用TCP/IP四层模型(实际开发中只涉及到四层模型,软件范畴涉及不到OSI七层参考模型): TCP是面向连接的通信协议,通过三次握手建立连接,通讯完成时要拆除连接,由于TCP是面向连接的所以只能用于端到端的通讯 具有高度的可靠性 三次握手,即通信时,客户端和服务端共计要传输三次包,三次握手建立连接: 1.主机(客户端)发送 SYN=1(建立连接标识)和seq=x(序号),客户端进入SYN_SEND状态,等待服务端确认

2019-03-27鱼鱼
算法:递归
算法:递归递归算法主要寻找: 终止条件:递归的尽头 单级递归的行为:在一次递归里要做的事情 返回值:每次迭代要return的东西 例如 首先,假定方法是已经实现的 终止条件为:当当前节点(传了空节点)或下一节点(传了单节点)为空,则无需反转返回当前节点 递归行为:假定之后的节点均已实现反转,则需要将已经反转的尾部的next变为当前节点,而当前节点由于是第一个节点,其next为null 此处注意在反转前需要先留存反转后的尾部; 返回值:返回反转后的头结点
![算法:递归]()
2020-06-24鱼鱼
Mybatis的缓存机制、redis数据库缓存实现和相关问题
Mybatis的缓存机制、redis数据库缓存实现和相关问题高并发环境下,数据库要承受非常大的压力,我们不能奢求每一次都只依赖分布式结构的读写分离数据库来解决问题,所以引入了数据库缓存的概念,这里的缓存不是具体的memcache或是redis,可能只是一块内存区域 此文介绍Mybatis的缓存机制 SqlSession是Mybatis创建数据库链接的会话,当度使用Mybatis需要对SqlSesssion的生命周期有一个把控,但是在Spring的集成中这个会话会被自动创建,周期只是对应一个方法(例如Service层的一个方法),所以每个请求就会对应一个或是多个SqlSession,SQLSession的主要实现是其中的Exector,对应了三种策略:
2020-03-03鱼鱼
算法1
算法1给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水 上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水) 木板组成水桶装水,定义高度为一数组,间隔为1,求水桶最大容量如[1,5,1,2,6,3]为15,解题思路:自两边木板向中间遍历求容量,每次相对短的木板向内移动,共比较n-2次 将水灌满,求灌满后的高度,其实就是从最高点向左右两个方向向中间遍历,依次求经过的最大值,这样一来就是从最高点向两侧递减的,再减去柱子原高度即可 容易理解的想法还有按高度分层计算,但是时间复杂度过高

2019-03-14Sherlock
Redis原理-源码解析:数据结构1 字符串操作&SDS及预分配的实现验证
Redis原理-源码解析:数据结构1 字符串操作&SDS及预分配的实现验证所有原理实现基于Redis版本6.0.9 SDS(Simple Dynamic String)简单动态字符串,是Redis中字符串所采取的数据结构,SDS并不是Redis的独创,只是被Redis采纳的一种数据结构,用以替换C语言原生的字符串类型:sds仓库传送门 使用方法与原生的C语言字符串类似,并能提供很多类似的API SDS经过了两个版本,目前的解析大都基于v1 v1版本的sds数据结构很简单: 比起C语言中单一的字符数组构成的字符串,sds具有以下优势: 存储了字符串长度,相比C语言遍历获取长度,将时间复杂度由O(n)变为O(1); 当SDS每次发生修改时,会为其分配冗余空间,在字符串空间小于1MB时,每次分配实际长度2倍的空间,而在大于1MB时则是分配多1MB的空间,是在空间不足时才会触发分配

2020-11-16鱼鱼
MySQL杂记
MySQL杂记Explain 可以分析一个SELECT语句的性能,只要加在查询语句之前即可,会输出关于查询语句的分析,分析这个例子: id: SELECT 查询的标识符. 每个 SELECT 都会自动分配一个唯一的标识符. select_type: SELECT 查询的类型. table: 所查询的表 partitions: 匹配的分区 type: join 类型 possible_keys: 此次查询中可能选用的索引 key: 此次查询中确切使用到的索引. key_len: 索引长度占字节数 ref: 哪个字段或常数与 key 一起被使用 rows: 显示此查询一共扫描了多少行. 这个是一个估计值.

2019-02-25鱼鱼
使用RPC与Restful接口调用服务
使用RPC与Restful接口调用服务在SOA和微服务架构中,远程通信是无法避免的,最常用的远程通信有两种方式: restful的接口,使用Http通信 使用dubbo或是Spring Cloud组件进行 RPC协议远程调用,可选地使用socket通信 不同的人对 RPC调用会有不同的看法,甚至对rpc本身的理解都不甚相同,但我认为 RPC有两种倾向: 一为语义化的 RPC 没有统一的请求规范,数据格式在开发人员中很难达成一致,在使用传统Http调用时,交互的双方需要约定一份“API文档”以保证数据格式的唯一性,这样API格式本身就成为了一道大墙,耽误研发双方的时间 但如果服务间采用语义化 RPC进行交互,双方可能并不需要一份文档,只要一份约定好的代码,并以此作为双方的依赖,在请求时也仅仅是直接调用方法本身,如此强的语义性怎能让人不爱
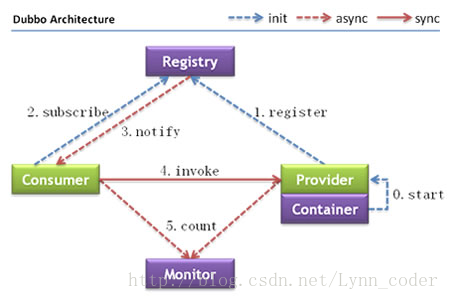
2021-01-13鱼鱼
CAT的使用和原理简介
CAT的使用和原理简介开发中刚好碰到了CAT的应用,利用这篇文章总结一下
![CAT的使用和原理简介]()
2019-08-07鱼鱼
