分布式系统一致性的分类
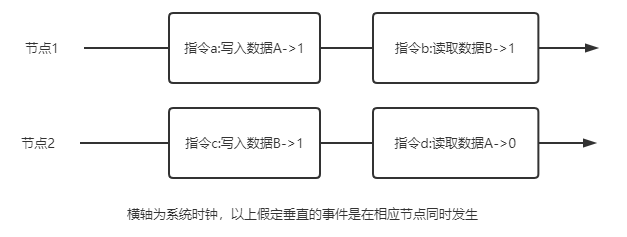
分布式系统一致性的分类在分布式系统中的CAP理论中有C(一致性),大郅表示分布式系统中节点状态或数据具有一致的特性 但一致性有着不同的分类,例如常见的用于取代CAP理论的BASE中的E,最终一致性,不同于强一致性,他强调着事务最终状态趋于一致,但中间态可能不一致,利用此篇文章总结一下分布式系统的一致性分类 根据实际系统的要求,分布式系统的一致性可以大致分为四类: 严格一致性 强一致性(线性一致/原子一致) 顺序一致性 弱一致性(最终一致性) 一个理想概念上的一致性,节点间数据完全一致,对外可表现为单个节点 由于网络延迟和通信等因素的存在,现实中这种一致性不可能存在 强一致性要求在全局时钟相同的条件下,对任何节点的读都相同且等于最后一次写成功的数据,这也就意味着仅仅在所有节点同步到数据后才会被标记为同步成功
2021-03-13鱼鱼
tips
tips一些小tip: 向上转型,失去特征 定义相同对象,重写hash和(不是或)equal Vue.nextTick() 回调函数:在Vue(重新)渲染页面之后调用 vue绑定样式,我们会发现background-color 不能直接绑定 需写为backgroundColor 因为js中不允许出现‘-’ 存库之前,mysql会把换行符什么的过滤掉,使得出入不一致(应用场景:textarea存)解决:this.value.replace(/\n|\r\n/g,"
") linux下的mysql的表名是区分大小写的! 实现线程接口 Runnable 注解注入失败 注解注入失败 Linux下缺少部分字体,使用drawString会出问题(二维码模块),解决手段:从windows引入字体,因为不是什么主流问题所以就简单写一下,如果再碰到相关问题在详细的讲述一下
![tips]()
2019-05-08鱼鱼
JVM的垃圾回收
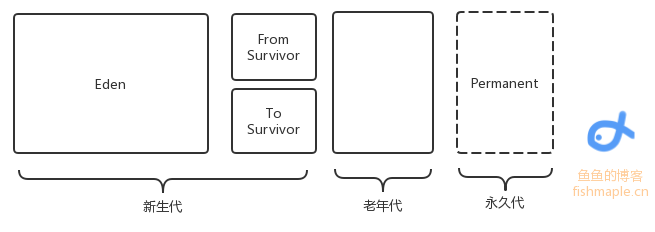
JVM的垃圾回收此文介绍Java的基本垃圾回收机制 GC主要回收的是堆区,在堆中是有对象分代的,一个对象每“逃”过一次回收,对象代数便+1,新生对象被称作新生代(如果是占据内存较大的对象直接定义为老年代),当代数一定时对象将由新生代变为老年代 同时在Java1.7之前还有永久代,保存了一些静态变量 总之,内存回收只发生在新生代和老年代之间 除了分代,内存也有分区: 如图,是内存区域分配,其中Eden存储了新建的小对象,当回收时,将Eden中存活的对象转移到To Survivor区中,将From Survivor中的代数高(一般是15)的存活对象转移到老年代中,代数没达到阈值的存活对象转移到To Survivor中
2021-04-07鱼鱼
MYSQL的索引、引擎的实现原理和应用
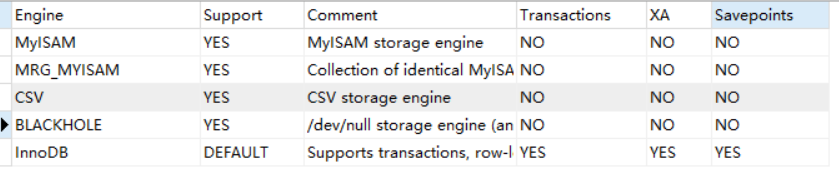
MYSQL的索引、引擎的实现原理和应用本篇主要介绍数据库MySQL的索引实现原理,包括B+ Tree的原理,顺带提到了数据库的常用引擎 我们常见的数据库引擎就是InnoDB,还有另外一个常见一个引擎叫做MyISAM,这里着重介绍着两个引擎,执行show engines,可见MySQL所有的引擎如下: InnoDB采用行级锁,不会记录表中的数据个数,支持外键,高并发下使用事务的首选引擎,也是5.5之后MySQL的默认引擎(之前采用MyISAM),可以通过bin-log日志回滚数据,所以它比较适合处理数据量大的数据 PS:InnoDB最初不支持全文索引,在MySQL 5.6版本后添加了支持 MyISAM跟InnoDB截然相反,它采用表锁,记录了表的条目数,SELECT COUNT可以直接查看表中数据个数,支持FULLTEXT索引,不支持外键和事务,不能进行数据恢复操作,他比较适合频繁插入的数据,或是读操作远大于写操作时
2019-09-15鱼鱼
杂记:Spring与Springboot的本地化配置
杂记:Spring与Springboot的本地化配置利用这篇文章巩固一下Spring框架的基础,因为发现接触到的各种Spring的项目配置杂七杂八,从xml到注解,从properties到json到yaml,他们各有千秋,没有哪一种方式可以绝对取代另一种配置,所以在这里统一介绍一下各种配置方式的内容和利弊,以便随时查看 这并不是一篇Spring框架领域的教程,只是一种技术的补足或是一种投机取巧的学习手段 原始的Spring是采用纯xml进行配置的,我从github上找了一个规范经典的SSM项目,以下是一些常用的配置,从这里就可以看出xml的基本格式: ApplicationContext-test.xml jdbc.properties

2020-03-01鱼鱼
Linux常见指令集和使用技巧(持续更新)
Linux常见指令集和使用技巧(持续更新)目前是一步一步记录用到了的Linux指令 | 管道,将符号前的指令输出作为符号后的指令输入 > 将正常输出重定向(比如指令打印内容输出到文件) >> 将正常输出追加重定向(区别与上面的覆盖,这个指令对于已经存在的文件会追加内容) & 后台执行 && 前面的指令执行完毕才执行后面的指令 || 前面的指令执行出错才执行后面的指令 ls 显示目录下的文件目录或者列出文件信息 ll 属于ls,列出目录下的所有文件信息 cd 进入目录 pwd 显示当前目录的绝对路径 mkdir 创建目录 rm 删除目录(慎) mv 移动目录 即文件的打包安装,对于不同的Linux系统使用的工具有所不同,此处使用ubuntu系统,利用apt工具进行打包

2019-09-09鱼鱼
过滤器、拦截器、监听器和AOP
过滤器、拦截器、监听器和AOP用这篇文章来梳理一下这些杂七杂八的Spring MVC中的基础概念,顺便讲一下在项目中的一些基本使用和常见应用(其实主要是针对AOP的),至于使用他们实现具体的功能,后续可能会独立写出来(谁知道呢) 执行的顺序: 项目初始化:filter:init()->filter:doFilter()->preHandle->Controller->postHandle->afterComplition ->destory() 过滤器(Filter),由servlet提供,拦截URL(其实是servlet),经过代理,执行想要的方法,最基本的使用是集成Filter类并重写方法,因为是从url层面上直接拦截,可以有很多用途,比如用于用户身份校验,比如某些页面需要有用户权限才能访问,就可以利用过滤器进行拦截,一些安全框架的鉴权本身也是过滤器的实现
![过滤器、拦截器、监听器和AOP]()
2020-03-01鱼鱼
使用RPC与Restful接口调用服务
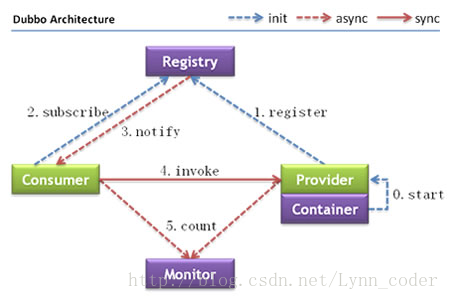
使用RPC与Restful接口调用服务在SOA和微服务架构中,远程通信是无法避免的,最常用的远程通信有两种方式: restful的接口,使用Http通信 使用dubbo或是Spring Cloud组件进行 RPC协议远程调用,可选地使用socket通信 不同的人对 RPC调用会有不同的看法,甚至对rpc本身的理解都不甚相同,但我认为 RPC有两种倾向: 一为语义化的 RPC 没有统一的请求规范,数据格式在开发人员中很难达成一致,在使用传统Http调用时,交互的双方需要约定一份“API文档”以保证数据格式的唯一性,这样API格式本身就成为了一道大墙,耽误研发双方的时间 但如果服务间采用语义化 RPC进行交互,双方可能并不需要一份文档,只要一份约定好的代码,并以此作为双方的依赖,在请求时也仅仅是直接调用方法本身,如此强的语义性怎能让人不爱
2021-01-13鱼鱼
多线程应用提高(II) 线程池
多线程应用提高(II) 线程池项目中,当发生并行操作时,一般都会用到线程池处理多线程任务,线程池的规则类似于数据库连接池,在此不予赘述 jdk自带线程池,此处主要讲述Spring框架自带的线程池ThreadPoolTaskExecutor 通过实现Runnable和Callable接口实现一个线程任务,从而能放入Executor进行线程管理 其中,Callable可以理解为带有返回值的Runnable,并且Callable需要实现的方法不是run()而是call(),该方法返回一个泛型对象 当我们把一个需要返回值的线程任务放进线程池后,线程池会返回一个Future对象,借助该对象,我们可以调用get()方法获取线程的状态,调用get()会阻塞当前线程直到返回结果
2020-02-25鱼鱼
网络协议面面观:TCP/IP协议组,TCP与UDP
网络协议面面观:TCP/IP协议组,TCP与UDP日常中的网站应用交互绝大部分都是基于TCP/IP协议栈构建的,而TCP/IP就是通信常见的protocol(协议)组,是一类协议的简称,利用这篇文章总结一些常见的TCP/IP网络协议簇以及着重一下两个常见的传输层协议TCP和UDP,扫一下盲 OSI参考模型是ISO(国际标准化组织)指定的网络互联七层模型,与此对比的还有互联网界针对TCP/IP协议簇提出的四层模型 相比之下,OSI七层模型的应用面很窄,且是一种理论模型,TCP/IP则是一种实施标准 一般使用四层模型来表达协议归属,所以此处不详细介绍七层模型的内容,只是简单的与四层协议做对比,两者对比: 应用层 通过这个TCP/IP模型,整体的数据流向是发送方自顶向下然后在接收方自底向上的,即:

2020-03-03鱼鱼
Springboot源码原理:从启动方法看配置加载
Springboot源码原理:从启动方法看配置加载首先看一个springboot项目的配置,我们可以定义一个application.yml,对于不同的环境有时也通过profile配置项指定不同的配置文件(譬如application-dev.yml),也可以通过命令行覆写具体的VM options配置项(举个栗子,启动时执行 java -jar xxx.jar --server.port=8080),此文讲解这些配制的读取原理 整体配置项的优先级从高到低为: 命令行配置; 系统属性(System.getProperties()) 系统环境变量 jar包外的主配置文件(带有) jar包内的主配置文件 jar包外的次要配置文件(由spring.profile指定的)

2021-03-09鱼鱼
Servlet线程模型与异步请求
Servlet线程模型与异步请求本篇文章主要意在整理Servlet的线程模型,帮助大家更好的理解请求在广泛使用的web容器下(基于Servlet的Tomcat服务器)的运行原理 Servlet是Java的服务端框架,可以利用Servlet来编写一个动态服务器(动态主要是区别于单纯的html构建的静态页面),主要基于Http协议 通过Servlet提供的API,我们可以轻松的处理网络请求和与其他服务建立连接(相比于基于Socket编程),并且基于Java使得它具有跨平台性、灵活性 简单的说Servlet就是一个封装了操作网络请求的API,它将Http网络请求简化为更容易处理的对象 从某种意义上讲,当我们不适用任何web框架(例如Spring mvc和Struts2)时,我们编写的每一个页面(jsp或是继承于HttpServlet的类)也都可以说是一个Servlet
![Servlet线程模型与异步请求]()
2020-03-23鱼鱼
