Elasticsearch 入门
Elasticsearch 入门(注:本篇文章基于Elasticsearch7.7.0版本,由于版本的差异性造成的内容不一致我会尽量在文中标出,但是) Elasticsearch是基于Lucene扩展的全文搜索引擎,当我们有对大数据量的处理和搜索时,全文搜索引擎是最佳的选择,同时他提供了高扩展性、高可用性、RestFul风格的API和友好的分布式部署配置,在此我们不予详述 我们日常使用的数据库索引是数据库一种编排数据(逻辑上)从而加快查询的手段,我们暂且将这种索引方式称为正排索引,他通过对待搜索字符寻址从而找到对应的数据 但是这种索引方式对于模糊匹配会出现"断档"现象(模糊符号后的片段无法走索引查找),并且对于海量数据无论在存储上还是在查找上都略显吃力,于是在Elasticsearch中引入了倒排索引来加快查询速度

2020-03-06鱼鱼
多线程应用提高(III) 并发编程的艺术
多线程应用提高(III) 并发编程的艺术《并发编程的艺术》p36:JMM不保证64位的long型和double型变量的写操作具有原子性 面试中可能经常会被问到HashMap和HashTable的区别,其中最重要的就是前者并不是线程安全的,但其实在高并发的情形下,后者的效率低的不像话甚至不可用,所以在jdk7之后出现了线程高效且安全的ConcurrentHashMap 当并发严重时,某线程若是调用了同步方法,另外的线程将进入阻塞/轮询状态,既不能put也不能get,但ConcurrentHashMap是不同的,它采用了锁的分段技术,将数据分段存储,不同的数据持有不同的锁,这样可用性会大大高于HashTable,所以在实际开发中我们都用ConcurrentHashMap取代HashTable
![多线程应用提高(III) 并发编程的艺术]()
2019-06-18鱼鱼
数据库的瓶颈问题解决(主从分离)与多数据源切换
数据库的瓶颈问题解决(主从分离)与多数据源切换业务中,数据库的设计是极为重要的一环,在高并发的业务中,我们可以采用集群部署来缓解请求和逻辑处理的压力,但是在数据库的层面却不行,Oracle、Mysql等数据库的吞吐量很高,但是依旧有阈值,我们不能奢求单库能解决所有的问题,假设遇到了数据库的瓶颈问题,我们可以采用怎样的手段呢 想要数据库达到瓶颈(SQL执行效率明显变慢),其实是很困难的,我们在程序的设计中基本都会使用到数据库连接池控制数据连接,但当业务量提升之后,连接池若是经常达到饱和便容易产生阻塞,我们不得不开放更多的连接数,随之而来的便是数据库承载了更多的并发,解决问题的主要方式有三: 更细的划分业务逻辑,将高频业务表单独分离开来,并通过定期清理的方式减小查询的执行时间,将不同的数据库请求分发到不同服务器的不同库,可以一定程度下解决上文所述的问题,但是应以数据库的设计性为前提,绝对不能牺牲原有设计合理的数据结构将其进行拆分,得不偿失

2019-08-29鱼鱼
常见树形结构
常见树形结构树形结构 相关术语 结点(Node):表示树中的数据元素,由数据项和数据元素之间的关系组成 在图中,共有10个结点 结点的度(Degree of Node):结点所拥有的子树的个数,在图中,结点A的度为3 树的度(Degree of Tree):树中各结点度的最大值 在图中,树的度为3 叶子结点(Leaf Node):度为0的结点,也叫终端结点 在图中,结点E、F、G、H、I、J都是叶子结点 分支结点(Branch Node):度不为0的结点,也叫非终端结点或内部结点 在图中,结点A、B、C、D是分支结点 孩子(Child):结点子树的根 在图中,结点B、C、D是结点A的孩子

2019-03-15鱼鱼
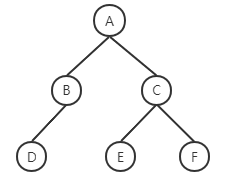
算法:广度优先搜索(BFS)(最短路径)
算法:广度优先搜索(BFS)(最短路径)我们先看一个案例: 遍历一个树结构,按层次输出树的节点内容,即:欲求 A B C D E F 实现方式便是从根节点(A)向下遍历,先获取A,其次是A的子节点B和C,其次是B的子节点D…… 这种遍历树结构或者图结构的方法被称作广度优先搜索(BFS),与之对应的先遍历到最下层子节点的是深度优先 BFS核心采用队列的数据结构,例如上面的树结构中,解法为: A进队列->A出队列 B、C进队列->B出队列 D进队列 ->C出队列 E、F进队列-> D、E、F出队列 如果想要区分层次边缘,使用count参数即可 解法步骤(蓝色部分为已经处理完的节点):
2020-06-05鱼鱼
Java的socket通信
Java的socket通信网络编程中,会使用socket通信 TCP/IP协议,即Transmission Control Protocol/Internet Protocol,传输控制协议/网际协议,他使用TCP/IP四层模型(实际开发中只涉及到四层模型,软件范畴涉及不到OSI七层参考模型): TCP是面向连接的通信协议,通过三次握手建立连接,通讯完成时要拆除连接,由于TCP是面向连接的所以只能用于端到端的通讯 具有高度的可靠性 三次握手,即通信时,客户端和服务端共计要传输三次包,三次握手建立连接: 1.主机(客户端)发送 SYN=1(建立连接标识)和seq=x(序号),客户端进入SYN_SEND状态,等待服务端确认

2019-03-27鱼鱼
算法:递归
算法:递归递归算法主要寻找: 终止条件:递归的尽头 单级递归的行为:在一次递归里要做的事情 返回值:每次迭代要return的东西 例如 首先,假定方法是已经实现的 终止条件为:当当前节点(传了空节点)或下一节点(传了单节点)为空,则无需反转返回当前节点 递归行为:假定之后的节点均已实现反转,则需要将已经反转的尾部的next变为当前节点,而当前节点由于是第一个节点,其next为null 此处注意在反转前需要先留存反转后的尾部; 返回值:返回反转后的头结点
![算法:递归]()
2020-06-24鱼鱼
MYSQL的索引、引擎的实现原理和应用
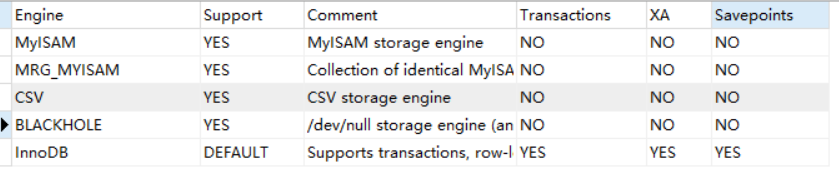
MYSQL的索引、引擎的实现原理和应用本篇主要介绍数据库MySQL的索引实现原理,包括B+ Tree的原理,顺带提到了数据库的常用引擎 我们常见的数据库引擎就是InnoDB,还有另外一个常见一个引擎叫做MyISAM,这里着重介绍着两个引擎,执行show engines,可见MySQL所有的引擎如下: InnoDB采用行级锁,不会记录表中的数据个数,支持外键,高并发下使用事务的首选引擎,也是5.5之后MySQL的默认引擎(之前采用MyISAM),可以通过bin-log日志回滚数据,所以它比较适合处理数据量大的数据 PS:InnoDB最初不支持全文索引,在MySQL 5.6版本后添加了支持 MyISAM跟InnoDB截然相反,它采用表锁,记录了表的条目数,SELECT COUNT可以直接查看表中数据个数,支持FULLTEXT索引,不支持外键和事务,不能进行数据恢复操作,他比较适合频繁插入的数据,或是读操作远大于写操作时
2019-09-15鱼鱼
Java中的动态代理与静态代理
Java中的动态代理与静态代理proxy(代理)作为一种设计模式在Java中已经应用非常广泛,例如常见的拦截器是代理模式设计的,AOP是通过动态代理实现的,而基于AOP的应用就更多了,从简单的事务应用到Dubbo框架,Java开发中离不开代理,本篇文章主要阐述Java中的代理,此处是比较狭义的代理,仅指方法和类中的代理 代理模式是一种非常常见的设计模式,它通过给某对象提供代理,从而通过代理对象控制原对象的引用 以下是代理模式的简单实现: 类Admin: 对应的代理类AdminProxy: 设计良好的聚合代理模式应该是代理类与被代理类共同继承一个接口,此处只为实现功能 这样在执行new AdminProxy().changeWorld()时,除了会调用原本的new Admin().changeWorld(),在方法前后也可以做出些其他的操作
![Java中的动态代理与静态代理]()
2019-08-09鱼鱼
mysql前缀索引
mysql前缀索引有时候需要索引很长的字符列,这会让索引变得大且慢 通常可以索引开始的部分字符,这样可以大大节约索引空间,从而提高索引效率 但这样也会降低索引的选择性 前面已经说过,使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本 2.1因为前缀索引无法完全等于判断,只是前缀匹配,所以可能需要扫描的所以数会增加 2.2在特殊的查询里面 select id,email from SUser where email='zhangssxyz@xxx.com'; 前缀索引需要回到 id 索引再查一下,因为系统并不确定前缀索引的定义是否截断了完整信息 select count(distinct left(email,4))as L4,

2020-05-15yangwcn
Consul API文档
Consul API文档这是一个记录Consul 常用API的文档,因为Consul的跨语言性,所以http API在Consul中尤为重要,此文档基于Consul版本1.6.0的v1 API,有其他的变化请参阅Consul官方API文档 Consul API采用经典的rest图谱Consul API版本只有一个版本,所以所有的前缀都为 /v1/,返回值以Json格式传输,可以添加pretty参数格式化Json,以本地部署为例,整体的baseUrl为127.0.0.1:8500/v1/ 获取代理成员列表和基本信息,类似于指令'consul members' 开启维护模式后,该代理节点将会被标注为不可用,可以用于上线前临时屏蔽node的服务

2019-12-01鱼鱼
什么是web服务器?什么是web应用服务器?容器、以及服务器概念的区分(萌新向)
什么是web服务器?什么是web应用服务器?容器、以及服务器概念的区分(萌新向)本文主要是为了帮助萌新理解在web开发时遇到的关于web工作原理的疑问,由于本人水平十分有限,所以本文仅作为一般性参考,如有错误,欢迎批评指正OVO 首先说明的是,我们所谓的web服务器并不是物理上的服务器,而是建立在物理服务器上的一个web应用的运行环境,是一个软件服务器 这就好比前后端分离开发时,后端模块在物理服务器上的JVM,前端也需要一个“运行环境”进行工作,那么web服务器端概念就应运而生了,大概就好比下图 上图中拥有VUE经典的原谅色的web服务器就是我们前端运行的地方,可见web服务器的主要作用是给前端一个合理的运行环境,其实不只是看起来那么简单,web服务器还要处理代理、反向代理、跨域、并支持并发等等

2019-06-16Agostino
