Java中的协程(虚拟线程)探究
Java中的协程(虚拟线程)探究在Java最新的LTS版本 21中,终于实装了协程这一特性 当然,在这些诸如python、golang等轻量级语言中被称为协程的东西,在Java中有个全新的代号——虚拟线程,为了将协程与线程做区分,在Java21中,原Thread被称之为平台线程 下文中,将统一使用线程/协程的方式称呼 我们都知道,Java中引入了线程的概念,区别于系统中的进程 作为并发执行的最小单元,在一定的条件下,使用多个线程同时运作可以有效提高程序的运转效率 而线程这一能力源于系统本身而并非JVM 之所以说是在一定条件下,是因为受限于机器配置情况(CPU的运作机制、核心数),线程的同时运作并不能线性的提升运行性能,单个cpu并不能同时处理多线程任务,实际的运作方式是基于时间片分片,各个线程抢占式执行代码,这样能减少一些无效的io等待(例如网络io、磁盘io实际是会阻塞等待io结果),同时在多核心场景下也能有效利用cpu
![Java中的协程(虚拟线程)探究]()
2024-10-28鱼鱼
kasper的算法(从0到1)
kasper的算法(从0到1)https://javaguide.cn/cs-basics/data-structure/linear-data-structure.html https://javaguide.cn/cs-basics/algorithms/linkedlist-algorithm-problems.html 项目地址:https://github.com/labuladong/fucking-algorithm 在线文档地址:https://labuladong.gitee.io/algo/home/ http://fishmaple.cn/blog/topicBlog?topicId=7
![kasper的算法(从0到1)]()
2023-10-23kasper
并发之AQS全解析
并发之AQS全解析我们知道juc(java.util.concurrent)包下有很多实用的类,提供了很多并发工具,例如线程池、原子类、并发工具、信号量工具、锁等,可以说基本实现都为悲观锁,底层原理基本都使用了AQS(AbstractQueuedSynchronizer),AQS不是一种概念,是并发中实打实的工具类 本篇文章针对AQS做解析 AQS是多线程访问共享资源的同步器框架 AQS的资源可以是独占的也可以是共享的 我们先来简单看一下它的使用方式和ApI(因为是抽象类,是不能直接使用的),下图是AQS的整体脉络 AQS核心就是一个状态值state,同时维护了一个线程的阻塞队列,队列的节点为有两种状态:SHARED(共享)和EXCLUSIVE(独占),节点状态有五种:
![并发之AQS全解析]()
2021-03-12鱼鱼
数据库的并发、锁机制与MVCC
数据库的并发、锁机制与MVCC在日常开发中,经常遇到数据库进行高并发操作的情况,但是我们处理并发一般都只在代码范畴而并不处理具体的数据库操作,这是因为数据库对基本的数据库操作做了锁处理,让我们可以忽略这一层的并发问题 详细可以参考Mysql的官方文档 注意:这一篇博客是针对MySQL数据库,且实用默认的 引擎InnoDb,使用其他数据库可能存在略微的差异 MySQL默认的数据库引擎InnoDB中Autocommit值为0(即自动提交事务)执行SQL语句的时候,每一条SQL语句都是一条单独的事务,所以并不存在并发的问题,数据库的锁机制已经做了很好的处理 但是当我们开启事务时,若不加处理,可能会产生一系列并发带来的问题

2021-01-24鱼鱼
阻塞队列与Protobuf的Udp通信 - 基于Cat的代理(Agent)项目拆解
阻塞队列与Protobuf的Udp通信 - 基于Cat的代理(Agent)项目拆解CAT是美团点评的一个基于Java开发的异常和性能监控项目,github地址:https://github.com/dianping/cat 本篇文章不是对CAT本身的源码拆解,而是基于本人依赖CAT client开发的代理项目进行拆解,但是并不会纰漏任何技术细节 CAT当前已有很多不同语言的Client,当然暂且是不 CAT本身是通过CAT client收集数据并上报至CAT server,server会进行并,共有六种常见数据格式:Transaction、Event、Problem、Metric、HeartBeat、调用链标记,其实如果不考虑复杂的处理(譬如Metric是可以基于指标生成折线图,Problem可以根据具体的异常类型追溯到相应的会话Track)除去Transaction剩余的数据格式都可以理解为特殊的Event

2020-07-19鱼鱼
Rocket MQ的基本应用
Rocket MQ的基本应用消息队列,常用于应用间通信 本篇文章基于RocketMQ官方文档 Topic:消息分类,依靠topic来定义消息类型 Tag:消息二级分类,可选,同个topic用不同的tag区分消息类别 Message : 泛指MQ所传送的消息体 Producer:消息生产者 Consumer:消息消费者 Name Server:有点类似于zookeeper,负责服务的注册与发现,维护Broker与Topic的映射关系 Broker:负责消息的存储与生产者消费者消息接收与分发,与Name Server建立长连接,保持心跳上传负责的topic信息 Producer:消息生产者,从Name Server获取Broker对应Topic映射关系,然后与Broker建立连接发送消息
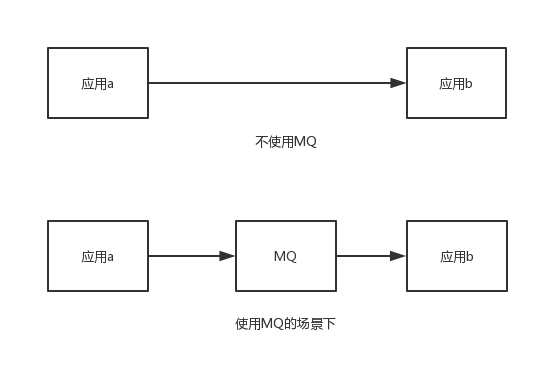
2019-06-28鱼鱼
代理与nginx
代理与nginx代理指接受请求但是不由代理服务器自己处理请求而是直接转发给指定服务器(或是根据负载均衡算法转发给集群部署中的某一台服务器),然后由代理服务器接收请求结果并返回给客户端 指客户端的代理处理方式,指用户通过代理服务器访问指定的网站、服务,最常见的应用是翻墙,并且使用这种方式可以使客户端匿名访问 指服务端的代理处理方式,多个用户在访问网站服务时,实际访问的是反向代理服务器(如nginx),反向代理服务器将请求内容转发给服务集群,最常用于服务器集群负载均衡和避免内网信息暴露 总之,正向代理是对服务端隐藏了客户端信息,反向代理则正相反,有一张图可以很好地概括这两个代理概念(图源知乎,侵删)
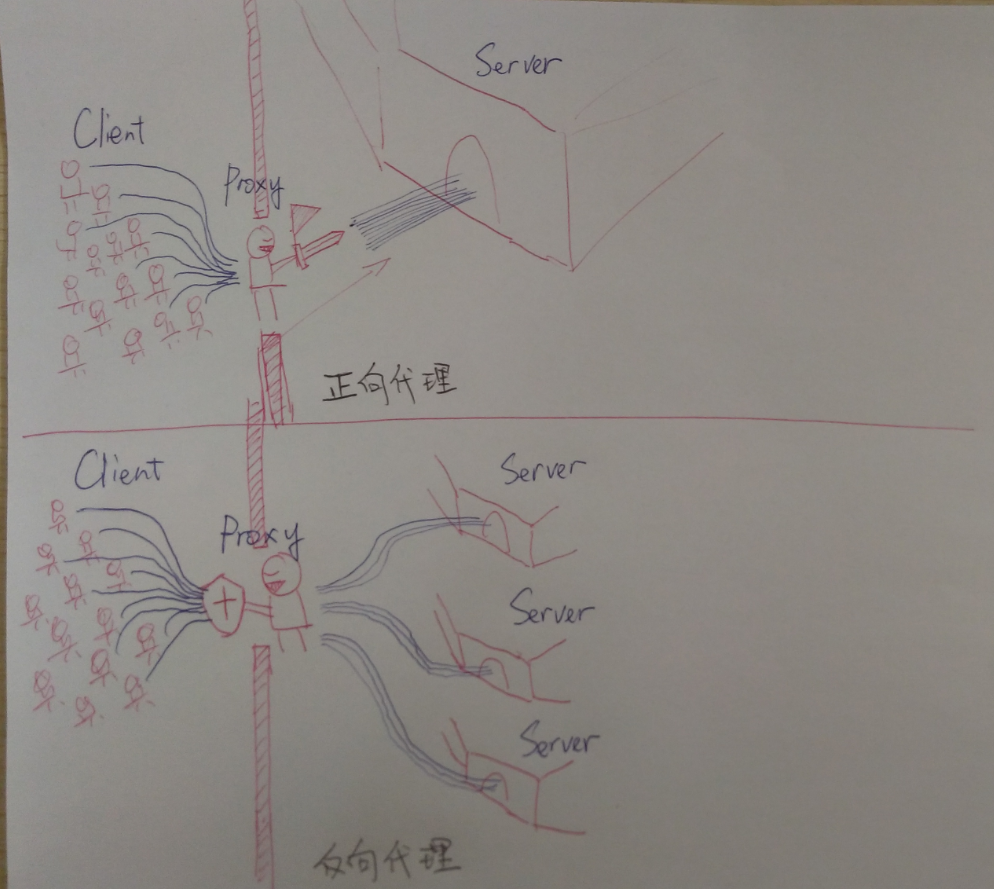
2019-05-11鱼鱼
tips
tips一些小tip: 向上转型,失去特征 定义相同对象,重写hash和(不是或)equal Vue.nextTick() 回调函数:在Vue(重新)渲染页面之后调用 vue绑定样式,我们会发现background-color 不能直接绑定 需写为backgroundColor 因为js中不允许出现‘-’ 存库之前,mysql会把换行符什么的过滤掉,使得出入不一致(应用场景:textarea存)解决:this.value.replace(/\n|\r\n/g,"
") linux下的mysql的表名是区分大小写的! 实现线程接口 Runnable 注解注入失败 注解注入失败 Linux下缺少部分字体,使用drawString会出问题(二维码模块),解决手段:从windows引入字体,因为不是什么主流问题所以就简单写一下,如果再碰到相关问题在详细的讲述一下
![tips]()
2019-05-08鱼鱼
什么是web服务器?什么是web应用服务器?容器、以及服务器概念的区分(萌新向)
什么是web服务器?什么是web应用服务器?容器、以及服务器概念的区分(萌新向)本文主要是为了帮助萌新理解在web开发时遇到的关于web工作原理的疑问,由于本人水平十分有限,所以本文仅作为一般性参考,如有错误,欢迎批评指正OVO 首先说明的是,我们所谓的web服务器并不是物理上的服务器,而是建立在物理服务器上的一个web应用的运行环境,是一个软件服务器 这就好比前后端分离开发时,后端模块在物理服务器上的JVM,前端也需要一个“运行环境”进行工作,那么web服务器端概念就应运而生了,大概就好比下图 上图中拥有VUE经典的原谅色的web服务器就是我们前端运行的地方,可见web服务器的主要作用是给前端一个合理的运行环境,其实不只是看起来那么简单,web服务器还要处理代理、反向代理、跨域、并支持并发等等

2019-06-16Agostino
Consul高级应用:多数据中心,模板与Client(Zuul)
Consul高级应用:多数据中心,模板与Client(Zuul)此文整理了Consul比较实用的高级功能:多数据中心,模板与维护模式 Consul提供了多数据中心联动的特性,目前看来多数据中心只是在查询阶段提现,各个数据中心的数据持久化和数据目录(k-v对)的更新不相干扰 也就是说,多数据中心的特性目前看来不能作为可用性的保障,当然 不排除可以手动热切换数据中心 最好判断是否使用多数据中心的情形是判断服务是否属于同一系统下,是否相同serviceId能提供相同的无状态服务,以下列举一些情景: 一个系统拥有多个域名的多套部署,提供版本一致的服务(建议使用多数据中心) 一个系统由多个服务器提供的不同服务提供(视服务具体情况,不建议使用多数据中心)

2020-01-28鱼鱼
造轮子0 浅谈设计模式
造轮子0 浅谈设计模式语义化接口的使用,譬如Aware等接口完全是语义性接口,不定义任何方法,只是用来约束一类行为 在Spring框架中有很多类似的接口 Wrapper,包装 ,相当于一个装饰器 XxxAware类表示在Spring中可感知,一般是类中需要用到Spring相关的对象时使用的 例如继承ApplicationContextAware接口后,实现setApplicationContext(ApplicationContext applicationContext)便会获得这个对象,与之对应的是XxxCapable类,继承他的类要负责实现相关的方get法负责生成Spring需要的对象
![造轮子0 浅谈设计模式]()
2019-05-26鱼鱼
排坑指南-异步操作HttpServletRequest丢失Cookie
排坑指南-异步操作HttpServletRequest丢失Cookie遇到了一个很奇怪的bug:请求鉴权失败,因为通过Request对象获取到的Cookie中没有数据 经过debug调用request.getCookies()方法返回了null值,但是header属性的cookie却能拿到用户的有效cookie(request.getHeader("cookie")),其中缘由,且慢慢道来 我们可以在web项目中通过Request对象很方便的获取Cookie对象: 但其内部实现其实有一层缓存逻辑,从名为"cookie"的请求头中读取并处理数据转为Cookie对象并不是个省时事,在org.apache.catalina.connector.Request类中可以看到如下代码实现:
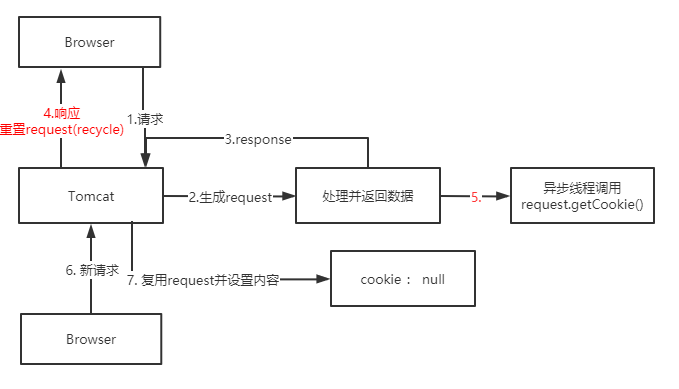
2020-11-11鱼鱼
