

在撰写脑裂问题相关的博客时发现脑裂问题的产生原因在不同算法下的分布式系统各不相同,需要先大致了解一致性算法并针对性的解决。市面上有很多开源的分布式系统,他们的数据一致性算法不尽相同,例如k-v系统的祖师爷——zookeeper采用的是ZAB的算法,而最近流行的Consul是raft算法,不同数据中心server沟通的方式则是gossip协议。不同的协议和方式对选举和数据同步有不同的处理机制,利用这篇文章来对比常见的分布式一致性算法。
一个系统可能会使用多个不同的一致性算法,以便于在不同的业务环节上有着各自更贴切的处理。
ps:有种观点是一致性算法不是很准确,因为replica也能保证数据某种程度上具有一致性,有人称之为共识算法。(一致性consistency,共识consensus)领会意思即可,后文皆使用一致性算法的称呼。
分布式中的常见问题
单点故障
单点故障,指一些常见的系统的仅有一个协调节点或是主数据节点,当这一节点发生故障,整个系统就会临时丧失可用性,直到选举出新的Leader节点,单点故障不是问题,问题是出现故障后如何更快的解决。
脑裂问题
脑裂问题,是指多个节点组成的分布式系统出现网络抖动、网络断连等问题时,多个集群间不互通,集群内的节点互通,因此选举出了多个Master(Leader),每次写入数据时,可能写入到不同的节点,因此会导致两节点数据不相同。这样当网络恢复后,就会有多于一个主节点,导致数据不能抉择而自动同步。
一个设计合理的分布式系统是不允许或是应以极小概率出现脑裂问题的。
拜占庭将军问题
事实上,一个分布式系统不该考虑拜占庭问题。分布式系统均基于共识达成一致,但假设共识出现了变差(譬如投票或是数据写入时信息被劫持或是软硬件错误)从而导致一些不可预料的问题(可以理解为:出了叛徒),此时从全局看可能分布式系统是一致性的,但是当前可用的多个节点中的“叛徒”节点数据可能是错误的,一但错误数据占多数或者从错误的节点直接读取数据,就会出现数据不一致的问题,解决拜占庭将军问题要从系统设计和安全性综合考虑。
分布式事务基础——2PC
2PC是一种分布式事务的解决方案,在这篇文章进行简单的回顾以便于更好的理解其中的一些概念和思想设计。
2PC(两阶段提交),是一种分布式系统一致性的数据提交方案,维持着分布式系统的一致性,他是有着一致性、原子性的中心化的协议。
2PC将数据提交事务大致分为投票阶段和提交阶段,在2PC协议中有两种角色:参与者(如在分布式系统的follower/slave)和协调者(如在分布式系统的leader/master),其中的参与者可以是功能不同的服务为了一致性而共同参与事务(譬如支付业务中的支付和订单服务),也可以是分布式系统中要保持数据同步的从节点。两个阶段:
第一个阶段,投票/提交。当产生新的数据写入请求,协调者会向参与者发送预请求,确认相关服务的存活可用状态。

第二个阶段,提交。当第一个阶段多数或是全部(视系统架构规则而定,严格的说2PC其实应该是全部可用)都为可用状态,协调者会提交相关的写入请求到参与者,并确认之前的存活服务均写入成功,一旦该过程有失败,则会发出回滚数据的请求。值得注意的是,回滚过程不属于2PC的过程,这也正是2PC实际存在的问题。
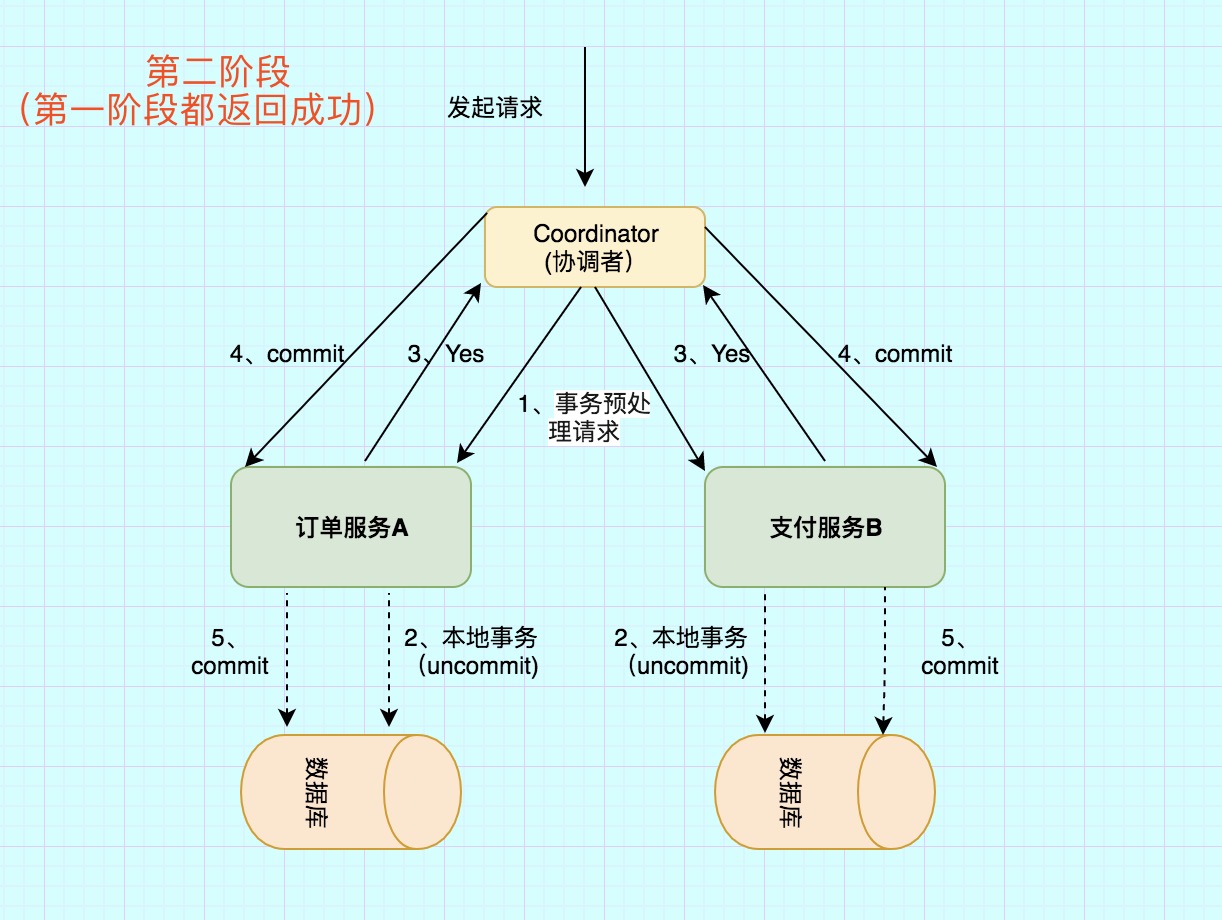
参考文章:分布式事务(1)---2PC和3PC原理
最初“完美”的一致性——Paxos算法
从数学的角度上看,仅有Paxos是“完美”的一致性算法(来源:知乎),但因其实现较为复杂,一般都采取工程上问题不大的其他一致性算法,后文的一致性都由Paxos演进而来。
Paxos的整体逻辑十分复杂以至于它更多情况下是数学问题,难以理解和实现,此篇文章暂时先不讨论此算法,因为在分布式系统中,它对于系统稳定要求较高,一般不采用此算法。
Zookeeper一致性——ZAB算法
在一个zookeeper集群中,有三种角色:Leader、Follower、Observer(观察者),其中Observer的角色可有可无,可在集群中手动指定。
首先看zookeeper集群的特性:
读写分离,zookeeper的写通过leader,读则是从follwer节点读取。
最终一致性,zookeeper节点选举过程中集群是不可用状态。
命令原子性,只有成功就是失败,没有部分成功的说法。
集群有序或是有状态,部署过zookeeper的都会了解到对于每一个节点都需要手动分配一个集群内唯一的id(myid)。
Zookeeper通过ZAB协议实现了一致性。大致原理有点类似于上面的2PC,原理图如下:
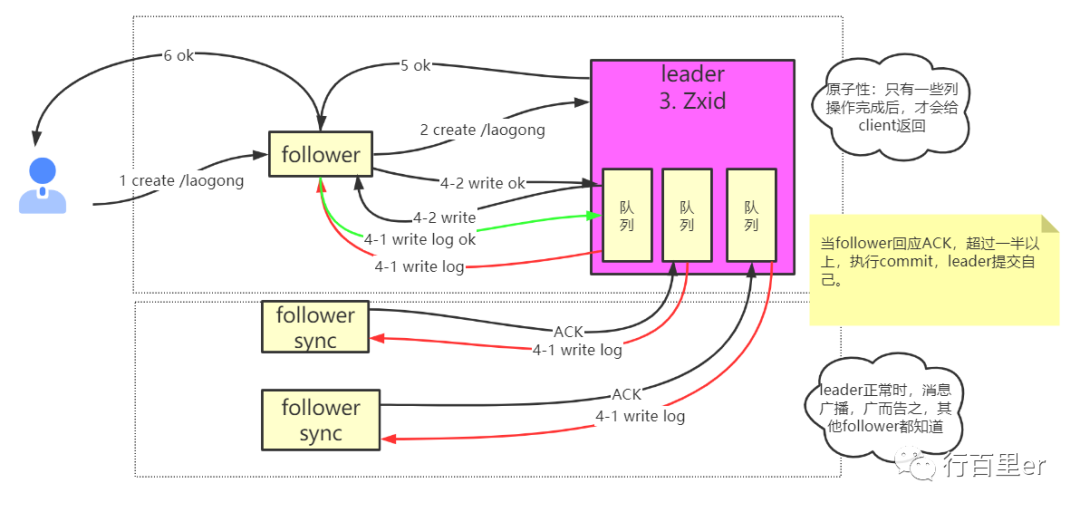
数据提交大致分为4步:
客户端发送请求,该请求会被路由至Leader节点;
Leader存储数据,并放入一个队列中,以保证数据的顺序性,随后将消息广播给Follower;
在正常情况下follower会传递ACK给leader,表明他已经消费并存储了这条数据;
当完成3步骤的节点多于集群节点数的一半时,会返回给客户端成功的标识,反之则是失败或超时。
这一步骤与上文所说的2PC十分相似,如果有少数的Follower发生宕机如上的架构也不会被破坏,失去联系的节点会被标注不可用,直到网络恢复并数据同步完毕。
故障恢复
很容易理解zk的Follower宕机使得集群故障时,只要等待网络回复即可。但是当Leader发生故障时呢?Zookeeper会产生单点故障问题,在Leader出现故障时,Zookeeper会重新进行Leader选举,选举规则很简单,有如下三条规则:
对于上文队列中每一条成功提交的数据都按顺序分配了id,优先选举数据id最新的,就是接受到数据最多的节点为Leader;
在1的基础上,如有多个节点,选取myid最大的;
依然是过半同意才能进行选举。
上文已经提到了Zookeeper任何操作都是过半同意机制(这里采取过半,是大于一半,不包含等于的情况),所以一个集群是绝非可能产生两个Master的,这种处理不存在脑裂问题。
此部分图片和内容参考博客:ZooKeeper原理-paxos算法,ZAB协议
主流的一致性——Raft算法
Raft是使用相当多的一致性算法,有人特意做过相关的可视化UI界面,可以帮助我们更好的理解这一算法。
Raft演示可视化和原理阐释(感觉讲的很详细): http://thesecretlivesofdata.com/raft/
Raft可操作交互UI(理解透彻):https://raft.github.io/
可以说多数开源的分布式系统都使用了Raft这一分布式算法,例如Consul、etcd等,因其规则简单却健全大受欢迎。
去中心化的最终一致性算法——Gossip算法
Gossip并不适用于所有分布式场景,它是一种P2P的一致性算法,Gossip并不具有强一致性,也就是相比前面的Raft或是ZAB,他不能保证一个事务在提交成功的时刻各节点对数据认同是一致的,因此,Gossip属于最终一致算法,常规的分布式情景使用Gossip会出现偶有数据不一致的问题。
那么,Gossip是用在哪里的?Consul系统将Gossip用的淋漓尽致,我们都知道作为k-v存储系统,其选主和数据事务都使用了Raft算法,但是其WAN(多个数据中心间)、LAN(节点间)通信、故障广播使用了Gossip算法。
Gossip译为八卦,其算法也如此,可以在有限的时间内,使用较少的路由传播事件,易于扩展,Gossip去中心化,不存在单点故障的问题,其具有天然的容灾性。
Gossip的实现我们以Consul为例:
每一个节点都会记录集群内部分其余随机n个节点的地址,所有被记录的节点公共集合会覆盖集群内所有机器,这样无需知道所有节点的地址。
每次收到新消息后,会将消息广播给这些地址,当然收到重复消息就不予理会了。
节点的宕机不会影响可用性和最终一致性,消息总能在合适的实际被广播出去。
图例如下:
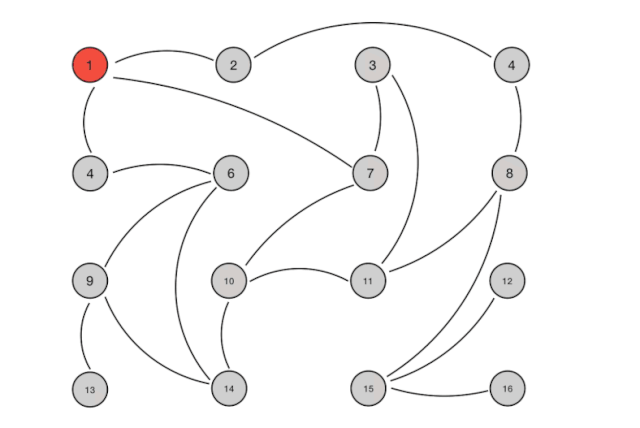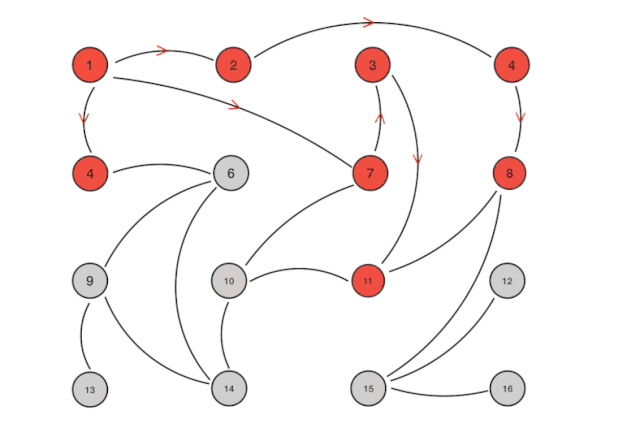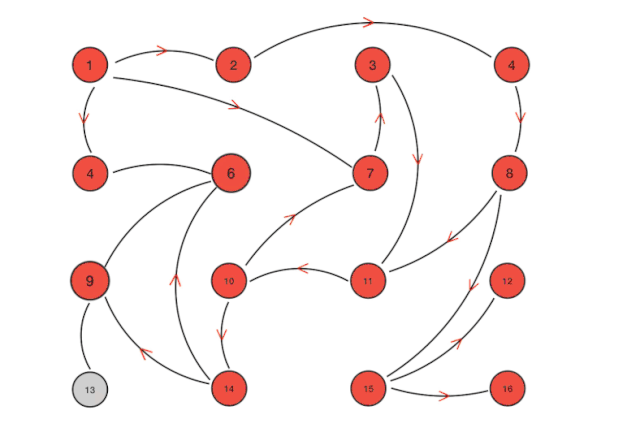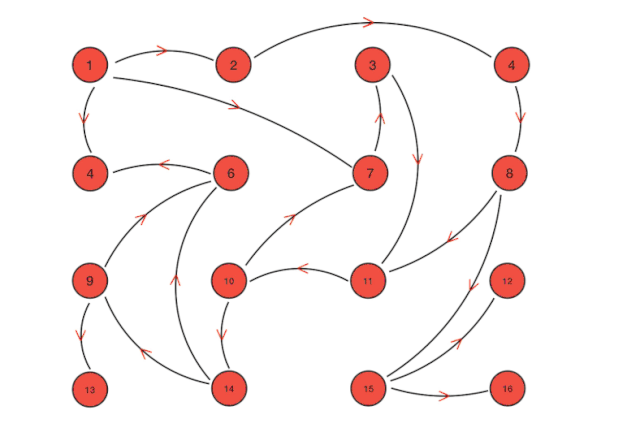
这样我们就很能理解它为什么不存在单点故障的问题了,去中心化的处理使得集群内有节点宕机一般不会影响到其他节点通信,一旦所有连接恢复正常,数据最终必将保持一致。譬如Consul集群中节点不可用的消息会很快被广播出去。近似随机的服务列表(我们管这个叫Gossip池)也受集群规模影响较小,用更多的通信延迟换来了较强的横向扩展性。
但是Consul中选主和数据存储却不能使用这样的协议,因为数据的提交必须保证一致。举例来说,如果Consul集群中超过一半节点通信不良,此时的集群应是部分只读状态,只读便是依靠Gossip实现的,否则便会像Zookeeper一样是不可用的,因此我们可以这样说,Consul的k-v数据是强一致性的,当过半节点宕机或进行Leader选举时不可用,但是Consul的集群状态数据是最终一致性的,当前时刻的节点故障数据可能还没有在各个节点间同步,我们在各个节点读取到的故障状态数据可能有所不同,但如果集群已经稳定下来,随着时间的推移,最终的故障数据总能一致(当然,既然被称作是最终一致,这个时间是不可预估的,当前的广播进度我们也并不知晓)。
Gossip协议部分参考: 简单介绍下consul底层的通信协议Gossip-腾讯云
 2021-03-13鱼鱼
2021-03-13鱼鱼