阿里巴巴Java开发手册 华山版 v1.5
阿里巴巴Java开发手册 华山版 v1.5
《Java 开发手册》是阿里巴巴集团技术团队的集体智慧结晶和经验总结,经历了多次大规模一线实战的检验及不断完善,公开到业界后,众多社区开发者踊跃参与,共同打磨完善,系统化地整理成册 现代软件行业的高速发展对开发者的综合素质要求越来越高,因为不仅是编程知识点,其它维度的知识点也会影响到软件的最终交付质量 比如:数据库的表结构和索引设计缺陷可能带来软件上的架构缺陷或性能风险;工程结构混乱导致后续维护艰难;没有鉴权的漏洞代码易被黑客攻击等等 所以本手册以 Java 开发者为中心视角,划分为编程规约、异常日志、单元测试、安全规约、MySQL 数据库、工程结构、设计规约七个维度,再根据内容特征,细分成若干二级子目录
2020-02-24鱼鱼
MYSQL的索引、引擎的实现原理和应用
MYSQL的索引、引擎的实现原理和应用
本篇主要介绍数据库MySQL的索引实现原理,包括B+ Tree的原理,顺带提到了数据库的常用引擎 我们常见的数据库引擎就是InnoDB,还有另外一个常见一个引擎叫做MyISAM,这里着重介绍着两个引擎,执行show engines,可见MySQL所有的引擎如下: InnoDB采用行级锁,不会记录表中的数据个数,支持外键,高并发下使用事务的首选引擎,也是5.5之后MySQL的默认引擎(之前采用MyISAM),可以通过bin-log日志回滚数据,所以它比较适合处理数据量大的数据 PS:InnoDB最初不支持全文索引,在MySQL 5.6版本后添加了支持 MyISAM跟InnoDB截然相反,它采用表锁,记录了表的条目数,SELECT COUNT可以直接查看表中数据个数,支持FULLTEXT索引,不支持外键和事务,不能进行数据恢复操作,他比较适合频繁插入的数据,或是读操作远大于写操作时
2019-09-15鱼鱼
分布式系统中的一致性算法和问题解决
分布式系统中的一致性算法和问题解决
在撰写脑裂问题相关的博客时发现脑裂问题的产生原因在不同算法下的分布式系统各不相同,需要先大致了解一致性算法并针对性的解决 市面上有很多开源的分布式系统,他们的数据一致性算法不尽相同,例如k-v系统的祖师爷——zookeeper采用的是ZAB的算法,而最近流行的Consul是raft算法,不同数据中心server沟通的方式则是gossip协议 不同的协议和方式对选举和数据同步有不同的处理机制,利用这篇文章来对比常见的分布式一致性算法 一个系统可能会使用多个不同的一致性算法,以便于在不同的业务环节上有着各自更贴切的处理 ps:有种观点是一致性算法不是很准确,因为replica也能保证数据某种程度上具有一致性,有人称之为共识算法
2021-03-13鱼鱼
DDD领域下的架构模式——CQRS架构
DDD领域下的架构模式——CQRS架构
//TODO
2021-06-24鱼鱼
Spring MVC源码和设计思想2 HandlerMapping
Spring MVC源码和设计思想2 HandlerMapping
系列传送门Spring MVC源码和设计思想1 DispatcherServlet-鱼鱼的博客 此篇篇幅很长,且慢慢道来 在之前一篇中,DispatchServlet的doDispatch()方法中有这么几行: 其中getHandler方法: handlerMappings是一个初始化过的List
,通过它获取HandlerExecutionChain HandlerExecutionChain存储了一个Object(其实就是HandleAdapter)和一个拦截器(HandlerInterceptor)数组,在doDispatch方法中执行了applyPreHandle和applyPostHandle方法,方法就是分别迭代调用了拦截器数组的postHandle和preHandle,同样地,发生异常时的triggerAfterCompletion也映射到了afterCompletion方法
2019-06-12鱼鱼
用Quartz 写定时任务
用Quartz 写定时任务
Quartz是OpenSymphony开源组织在Job scheduling领域的一个开源项目,是一款清新友好的任务调度框架 Quartz两大基本功能是job和SimpleTrigger(作业和触发器) 核心的是Scheduler类 有以下几个相关类: Scheduler:定时任务调度; Job:任务类需要实现的接口; JobDetail:Job的实例,被Scheduler执行的是JobDetail,而不是Job; Trigger:触发Job的执行; JobBuilder:定义和创建JobDetail实例的接口; TriggerBuilder:定义和创建Trigger实例的接口;
2019-06-18鱼鱼
杂记:Spring与Springboot的本地化配置
杂记:Spring与Springboot的本地化配置
利用这篇文章巩固一下Spring框架的基础,因为发现接触到的各种Spring的项目配置杂七杂八,从xml到注解,从properties到json到yaml,他们各有千秋,没有哪一种方式可以绝对取代另一种配置,所以在这里统一介绍一下各种配置方式的内容和利弊,以便随时查看 这并不是一篇Spring框架领域的教程,只是一种技术的补足或是一种投机取巧的学习手段 原始的Spring是采用纯xml进行配置的,我从github上找了一个规范经典的SSM项目,以下是一些常用的配置,从这里就可以看出xml的基本格式: ApplicationContext-test.xml jdbc.properties
2020-03-01鱼鱼
排坑指南-异步操作HttpServletRequest丢失Cookie
排坑指南-异步操作HttpServletRequest丢失Cookie
遇到了一个很奇怪的bug:请求鉴权失败,因为通过Request对象获取到的Cookie中没有数据 经过debug调用request.getCookies()方法返回了null值,但是header属性的cookie却能拿到用户的有效cookie(request.getHeader("cookie")),其中缘由,且慢慢道来 我们可以在web项目中通过Request对象很方便的获取Cookie对象: 但其内部实现其实有一层缓存逻辑,从名为"cookie"的请求头中读取并处理数据转为Cookie对象并不是个省时事,在org.apache.catalina.connector.Request类中可以看到如下代码实现:
2020-11-11鱼鱼
JVM源码解析 从Launcher类浅谈ClassLoader(类加载器及双亲委派)
JVM源码解析 从Launcher类浅谈ClassLoader(类加载器及双亲委派)
首先普及ClassLoader的基础:所有的Java类都是由ClassLoader由class文件加载进内存的,对于一个类,其唯一标识就是类名+加载他的ClassLoader(亦即对于不同的 ClassLoader,即使是加载了同一个Class也不能互通,本质上是两个类),其基本的分类如下图: BootstrapClassLoader是一个特殊的ClassLoader,负责启动时加载jre的类库 并不继承于ClassLoader,因为是jvm逻辑的一部分; ExtClassLoader也会加载jre类库,但是会加载那些额外的扩展类库(jre\lib\ext目录),到这个级别的 类加载器已经可以直接在代码中使用了;
2020-11-28鱼鱼
待办事宜
待办事宜
2018-10-18 解决XSS攻击问题(v-html) 针对缺省有所设置(blog:page等) 添加新增按钮 添加置顶 解决日志编辑首行出现空格 开发射线:一个匿名交流板 留言 联系方式 可回复 筑楼 时限性 超时关闭 匿名 默认匿名 字典: 可标注,添加富文本新组件字典(视情况添加 工作量难以预估 可考量在全网) 字典包括 可见性(待定),条目,解释,相关词条 必须可编辑 添加不同风格 参照http://www.unconstraint.cn/,github两种风格可切换 流动 简约 重金属 使用图床存储较大的图片(RECOMMEND:使用新浪微博)
2019-03-24鱼鱼
JVM源码解析(2) ContextClassLoader与ClassUtil.forName()方法浅析
JVM源码解析(2) ContextClassLoader与ClassUtil.forName()方法浅析
在Spring获取Context的源代码中,我们看到了对ClassUtil的方法调用,通过给定ClassName和ClassLoader进行Class的加载: ClassUtil.forName是仅供于Spring内部使用的获取Class对象的方法,来看一下源码: 首先 对于缓存的Class一块,在类的静态块中就能看出其逻辑: 在上面的resolvePrimitiveClassName方法中,先对长度做了一个判断,因为较长的packagename会影响执行的性能: 最终加载Class依旧是通过ClassLoader的,先来看一下获取ClassLoader的方法实现: 此处优先使用了ContextClassLoader作为 类加载器而非默认的AppClassLoader,在JVM源码解析 从 Launcher类浅谈ClassLoader中,提到了关于 类加载器的相关知识,使用ContextClassLoader是为了弥补双亲委派加载机制的对于自定义 类加载器的缺憾:那些自定义的 类加载器并没有机会上场,在使用了AppClassLoader后我们的自定义ClassLoader所加载的Class是无法被加载进去的,使用ContextClassLoader,我们可以在定义线程时,通过Thread的init方法(子线程调用,私有方法)或是setContextClassLoader直接指定使用自定义的ClassLoader
2020-08-16鱼鱼
[Quick Start]RedisTemplate的bean手动配置
[Quick Start]RedisTemplate的bean手动配置
有时我们可能需要手动配置Redis的连接,例如动态修改或是从特殊的参数中获取,而不是使用SpringBoot的自有配置,此篇文章意在快速指引redis的手动配置 基于Spring项目和Jedis的底层,使用RedisTemplate; 通过Maven引入相关依赖,可以的话spring-data-redis选择2.0.0以上版本,较低版本需要的依赖: 如果使用了Spring-boot并且要使用较高的版本(例如在2.1.0后才有的某些API-putIfAbsent带有超时时间的版本),我们直接修改starter的版本是不够的,二者版本并不对称,我们需要去掉其中的redis依赖并单独引入 建议保持良好的依赖管理习惯,显式的移除依赖,而不是任其覆盖,如:
2020-02-24鱼鱼
网站地图
1
首页
博客
{{screen}}
第 {{page}} 页
博客索引
{{blog.title}}
{{blog.content}}
{{blog.createDate}} ◔ {{blog.timeline}}
{{blog.author}}
{{tag}}
{{blog.likeCount}}
{{blog.commentCount}}
分类下暂时没有文章哦!
主题分类
源码解析
造个轮子吧
多线程应用提高
问题探究
来做几道算法题
微服务架构实战
QuickStart
电子出版物
Java排坑指南
做点有趣的!
瞧瞧看看MySQL
{{taggroup.label}}
{{tag.value}}

 2020-02-24鱼鱼
2020-02-24鱼鱼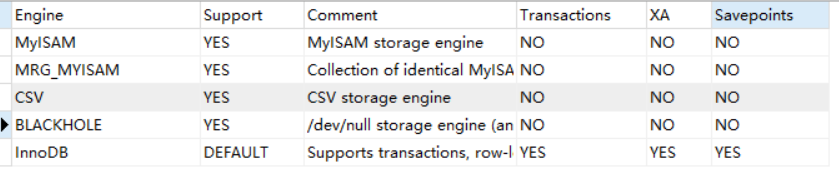 2019-09-15鱼鱼
2019-09-15鱼鱼 2021-03-13鱼鱼
2021-03-13鱼鱼 2019-06-18鱼鱼
2019-06-18鱼鱼 2020-03-01鱼鱼
2020-03-01鱼鱼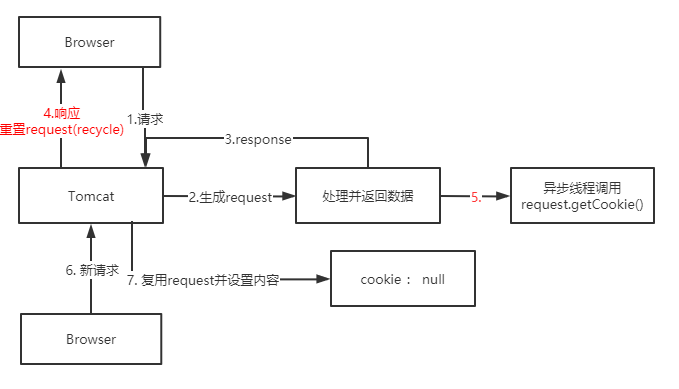 2020-11-11鱼鱼
2020-11-11鱼鱼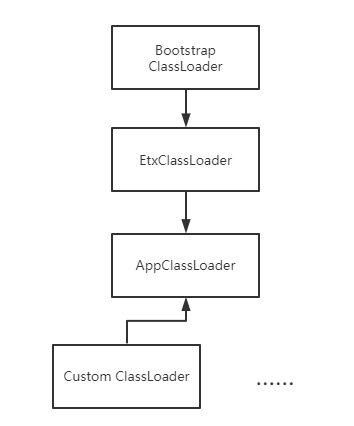 2020-11-28鱼鱼
2020-11-28鱼鱼![[Quick Start]RedisTemplate的bean手动配置](/blog_cover/20200220/bc7458d39b07471f8559d5469418133f.png) 2020-02-24鱼鱼
2020-02-24鱼鱼