

(注:本篇文章基于Elasticsearch7.7.0版本,由于版本的差异性造成的内容不一致我会尽量在文中标出,但是)
Elasticsearch是什么-es的基础概念
Elasticsearch是基于Lucene扩展的全文搜索引擎,当我们有对大数据量的处理和搜索时,全文搜索引擎是最佳的选择,同时他提供了高扩展性、高可用性、RestFul风格的API和友好的分布式部署配置,在此我们不予详述。
速度提升的原理:倒排索引
我们日常使用的数据库索引是数据库一种编排数据(逻辑上)从而加快查询的手段,我们暂且将这种索引方式称为正排索引,他通过对待搜索字符寻址从而找到对应的数据。但是这种索引方式对于模糊匹配会出现"断档"现象(模糊符号后的片段无法走索引查找),并且对于海量数据无论在存储上还是在查找上都略显吃力,于是在Elasticsearch中引入了倒排索引来加快查询速度。
倒排索引存入的数据键并不是数据本身,而是经过对数据分析后提取到的keyword,例如:“我爱中国”会被分解为“我”、“爱”、“中国”(期间可能会丢弃部分无语意的助词或是对词汇进行转换,既为了压缩空间,也能更好的模糊匹配,见后文)而在索引文件中会记录下这些关键词出现的位置(出现在哪条数据以及可能记录出现在数据中的次数和位置),当我们进行搜索时,也会用同样的手段拆分搜索词,然后找寻对应的索引。当然,这只是对倒排索引的道理梗概,实际处理的逻辑和结构都比这里的描述要复杂得多。
相关概念
索引词 term:是一个进行精确搜索的词汇,区分大小写。
文本 text:es存储的原结构,文本会被分解成一个个的索引词存在es的索引库中。
文档 document:es中存储的JSON字符串,是数据的内容体现,每个文档都是一个具体的对象,相当于数据表中的一行数据。
索引 index:结构相同的文档集合,有点类似于数据库的表。
类型 type:同个索引下的多个类型,相当于索引的分区,这个相比数据表更为细化。type这一特性在ES7版本之后之后已经被废弃掉了。
映射 mapping:每个索引对应着一个映射,定义了索引对应的结构,相当于数据库的表结构。
主键 id:同数据库的主键,文档的唯一标识。
字段 field:一个文档包含多个字段,相当于数据库的字段,但是es中的字段可以很复杂(比如可以是一个对象)。
分布式和优化相关:分片和复制
如此的一个引擎库不可能是仅支持单节点的,所以针对ES的每一条个索引,都有一个参数number_of_replica,这个概念有点类似于Kafka的Replication Factor(不知道也不要紧),它代表了当前索引库的额外副本数,数据将会在副本服务上复制,如果索引库的该值为0,则说明此库仅单节点存储,所以此值应该不得大于ES的节点数-1。
另有一个参数number_of_shards,这有点类似于Kafka的Partitions概念,他代表了数据的分片数,可以理解为一种索引数据的逻辑分割,譬如ES有五个分片,他会将数据较为均匀的分摊到五个分片中。他的作用主要是能在查询数据时将请求分发至多个副本下从而提升性能,例如,一个索引库的额外副本数为1,分片数为5,则共有5*2套分片,在下发查询请求时,会按照不同的分片分发给多个ES服务,一般是在一台服务器的三个分片中查询数据,在另一台机器的另两个分片中查询,然后整合数据并返回,这样同时两台服务器处理搜索请求,会更加高效。
es的数据类型
text,文本类型,最最基本的数据类型,也是es搜索关键所在的类型,定义一段字符串,会被分词,全文搜索的字段应该使用此数据类型。
keyword,文本类型,顾名思义,存储的便代表关键词,类似于较短的varchar,可以进行排序等操作,但是不会被分词,一般都是较短的数据全匹配。
数字类型,统一说下:byte、short、integer、long、float、double、half_float、scaled_float,scaled_float是带有缩放因子(scaling_factor)的float,最终取值为值x缩放因子。
data,日期类型,格式比较随意,存入的时候可以是时间戳(注意时区),也可以是能被识别为时间的字符串。
boolean,布尔类型,格式也很随意,例如:true、yes、1等均表示true,false、no、0等均表示false。
binary,二进制,只用来存储数据,不能通过这个字段被搜索到。
range类型,代表一个范围,规定了值的前后范围
integer_range long_range float_range double_range date_range 日期的范围 ip_range ip值的范围,支持ipv4和ipv6 数组类型,同json的数组,数组只能是同种格式数据的集合。
对象类型,其实一个文档就是一个对象,对象类型可以理解为嵌套对象。
es中的数据类型有很多,还有很多领域专用的数据类型,在此只列举除了常用的类型。
Elasticsearch的REST API使用指南
其实这部分相当于把API文档搬过来了,baseUrl若使用本地的es便是localhost:9200。在url中,使用_后接关键词从而与索引、类名区分开来。
基础参数与基本约定
es API提供了一些通用的基础参数:
v,table格式结果中显示表头
help,table格式结果可能的所有列展示
h=,指定要显示的列
pretty,json格式结果进行格式美化,对直接使用浏览器访问get接口的小伙伴很友好
大体使用rest api风格接口进行通信,
综述:状态查询
GET /_cat 列表展示
展示集群监控相关的状态接口列表,通过接口可以查询相关的es状态,比如:
GET /_cat/indices?v 查看索引状态
可以查看当前es索引的状态,加上v后展示table的表头,结果如下(index是索引名,这里省略掉了):
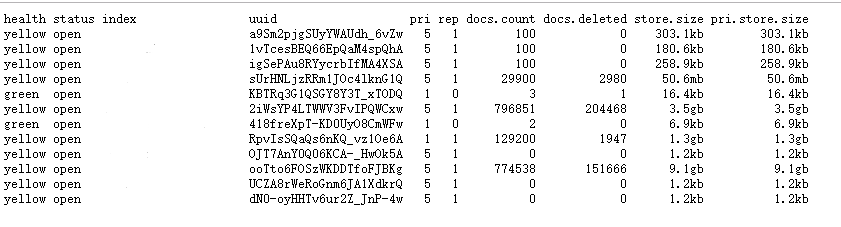
其中,pri表示主分片数量,rep表示副分片数量,docs.count表示当前索引的文档总数量,docs.deleted表示删除文档数(个人比较倾向于表示待删除的文档数,因为实际已经删除的文档是不会记录在里面的,该值应该是表示仍在占用存储空间但是实际不会用到的文档数量,没有覆盖和删除操作后期数字会渐渐变小),store.size表示总分片存储空间大小,相应地,pri.store.size表示主分片存储空间大小。
索引相关
PUT /{indexname} 创建一个索引
在请求体中,可以直接传入索引的setting(这个在后文会说),
DELETE /{indexname} 删除一个索引
GET /{indexname} 查询索引信息
展示索引的基本信息,包括setting、mapping等。
//TODO
参考书籍:《Elasticsearch技术解析与实战》
 2020-03-06鱼鱼
2020-03-06鱼鱼