

若不提到Jdk版本,本文中的源码都是基于jdk8版本分析的。
注:有关同步集合(如Vector、ConcurrentHashMap、CopyOnWriteArrayList等)请移步博客。
List
数组集合类,是Collection接口的子类,有序的Collection实现,包含ArrayList、LinkedList、Vector,其中Vector是线程安全的ArrayList,LinkedList是底层基于双向链表实现的List。
ArrayList的默认大小为10,扩容操作:
int newCapacity = oldCapacity + (oldCapacity >> 1);
也就是1.5倍。
Set
不重复集合类,不能包含重复的元素,是Collection接口的子类,包含HashSet、LinkedHashSet、TreeSet,其实都是基于Map类的实现,所以详细了解请参阅Map类。
HashSet
HashSet是基于HashMap的实现,不保证元素的迭代顺序,是无序的实现,Set的值其实就是HashMap中的key(value都是一个默认的无用Object),所以了解其原理只要看HashMap即可。
LinkedHashSet
是HashSet的子类,需要维护底层的HashMap和双向链表,是有序的,实现等同于LinkedHashMap,所以性能稍逊色于HashSet。
TreeSet
是TreeMap的实现。
Queue
队列,常见实现ConcorrentLinkedQueue,Deque(的子类ArrayDeque)相关方法:
| 失败时会抛出异常 | 返回空值(false) | |
| 入队列 | add | offer |
| 出队列(移除队首元素) | remove | poll |
| 获取队首元素 | element | peek |
offer(value)方法更适合那种无界队列,在不同的类中实现是不相同的,有时两方法的实现是相同的。
实现:ConcorrentLinkedQueue用CAS算法和链表实现线程安全的队列。
Deque
Deque被叫做双端队列,同时拥有队列和栈的特性。ArrayDeque是使用数组存储的双端队列,值不可为空,方法可以定义队列头尾,如addLast,poolFirst等,类中的属性head和tail使用位操作,是一个高效的队列类,同时也可用于栈等数据结构。
阻塞队列BlockingQueue
阻塞队列会单独讲述
Stack
栈,先入后出,继承自Vector,所以实现十分本身是线程安全的(synchronized)。
Map
最重要的数据结构,键值对,包含HashMap、LinkedHashMap、TreeMap、HashTable、ConcurrentHashMap等。
HashMap
是用的最多的数据结构,无序,线程不安全,key可为null,介绍之前需要先了解一下HashMap的底层数据结构:
底层由多个bucket构成一个数组,每个bucket中的结构是单向链表或是红黑树,链表或是红黑树中存储着Entry,也就是键值对们,示意图如下:
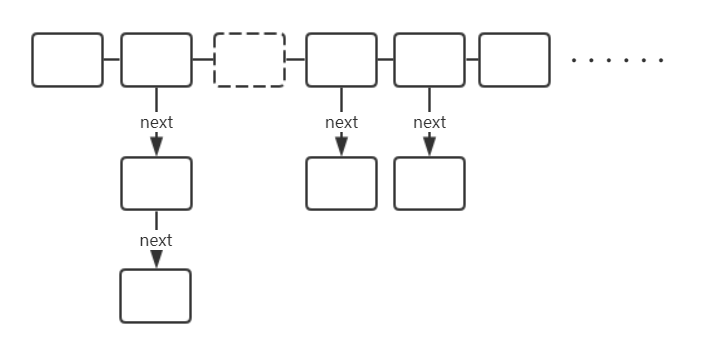
横向为数组,纵向为单向链表,每个纵向是一个bucket,每一个实线格子都代表一个Entry,虚线位置代表无元素但占位,这里没有展示红黑树,当链表中的元素个数大于8,将采取红黑树的方式存储,注意在jdk7之前的版本中,统一采用数组+链表存储。
Entry结构如下:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
// ………………
}
在插入元素时,根据元素key的hash与总大小(横向宽度)取余,根据得到的结果插入对应的bucket中(插入红黑树中或是链表尾部),遍历链表中如有相同的key会直接覆盖掉value值,hash算法:
x mod 2^n = x & (2^n - 1) (用位运算取余效率较高)
默认大小为16(数组长度):
/** * The default initial capacity - MUST be a power of two. */ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
HashMap的扩容并不是固定的,而是综合依照很多参数扩容的,这里着重看一下扩容,我在方法doc中解释了几个参数:
/**
* Initializes or doubles table size. If null, allocates in
* accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
*
* @return the table
*/
//capacity :bucket数量,即数组大小,默认1 << 4,即16
//loadFactor : 装载因子,默认0.75f;
//threshold :threshold=capacity*loadFactor;默认是零,后面会进行计算
// 当size大于此值时会进行resize
//
final Node<K,V>[] resize() {
//table指当前表
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) { //进行过扩容
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
//size翻倍
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // 若手动设定过threshold,initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) { // 手动设定过threshold的首次扩容
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
//新的threshold 首次:capacity*loadFactor 其后:*2
threshold = newThr;
//新的capacity 即数组大小
// 首次(定义数组):threshold 首次为自定义threshold :16 之后:翻倍 超出:不扩容
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null) //仅含单一元素的节点
newTab[e.hash & (newCap - 1)] = e; //迁移新的节点
else if (e instanceof TreeNode) //红黑树节点
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
ConcurrentHashMap与HashTable
HashTable是线程安全的HashMap,使用了重量级锁synchronized并且规定key值不可为空,在并发环境下,synchronized的表现十分臃肿,容易出现阻塞现象,推荐使用ConcurrentHashMap,它在HashMap的基础上引入了分段锁,不同的数据端对应不同的锁,有效的提高了性能。
ConcurrentHashMap在jdk1.8之后的版本中锁的粒度等同于bucket的数量,利用volatile和native方法getObjectVolatile(Object,long)实现,在Node中,key和hash值都是final修饰的,只有val和next是volatile的。
LinkedHashMap
我们都知道LinkedHashMap是能保证访问顺序与插入顺序一致的一种数据结构,但其实它的底层实现与HashMap是一致的,只是同时按插入顺序另外维护了一个双向链表,在迭代时按照那个链表的顺序输出。以下的图片能帮助我们很好地理解这一点(图片来源:图解LinkedHashMap原理 - 简书):
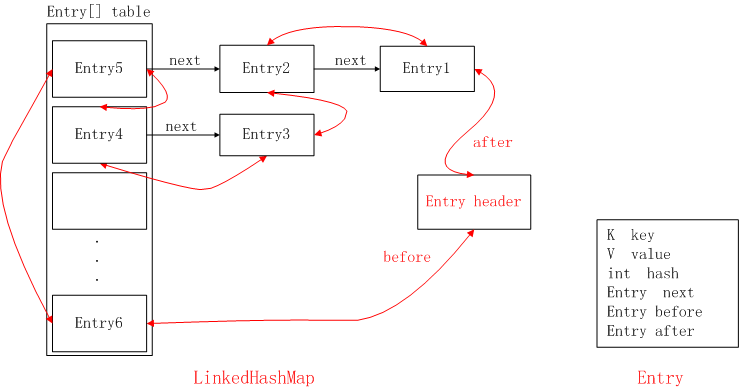
当删除或更新(链表中先删除后再表尾插入),对应的双向链表顺序也会做出相应处理。
综述
扩容时机和扩容量
首先扩容应该仅针对数组格式的集合,即HashMap、ArrayList。
ArrayList的初始容量默认为10(可设定),每次扩容为1.5倍;HashMap的初始bucket.length为16,loadFactory为0.75f,每当size为这两个属性乘积时进行扩容。
equals()方法
对于Map,在size相同的情况下,使用迭代器比较每一个元素的key和value对应在另一个Map中是否存在、相等,所以对于HashMap只要键值对组合相同,不管排列顺序,哪怕Map类型不同也会返回true