盘点redis中特殊的数据类型 HyperLogLog Bitmap
盘点redis中特殊的数据类型 HyperLogLog Bitmap 基数计数(cardinality counting)通常用来统计一个集合中不重复的元素个数,例如统计某个网站的UV,或者用户搜索网站的关键词数量 数据分析、网络监控及数据库优化等领域都会涉及到基数计数的需求 要实现基数计数,最简单的做法是记录集合中所有不重复的元素集合S_uSu,当新来一个元素x_ixi,若S_uSu中不包含元素x_ixi,则将x_ixi加入S_uSu,否则不加入,计数值就是S_uSu的元素数量 这种做法存在两个问题: 当统计的数据量变大时,相应的存储内存也会线性增长 当集合S_uSu变大,判断其是否包含新加入元素x_ixi的成本变大 大数据量背景下,要实现基数计数,首先需要确定存储统计数据的方案,以及如何根据存储的数据计算基数值;另外还有一些场景下需要融合多个独立统计的基数值,例如对一个网站分别统计了三天的UV,现在需要知道这三天的UV总量是多少,怎么融合多个统计值
![盘点redis中特殊的数据类型 HyperLogLog Bitmap]()
2022-01-12鱼鱼
DDD领域下的架构模式——CQRS架构
DDD领域下的架构模式——CQRS架构//TODO
![DDD领域下的架构模式——CQRS架构]()
2021-06-24鱼鱼
扫盲——加密那些事
扫盲——加密那些事扫盲加密解密算法 日常开发中我们经常接触MD5算法,以此进行简单的文件完整性校验或者是后台密码验证,MD5是最常见也是最简单快捷的散列算法,常用于参数或文件完整性校验,譬如网络请求发起方与接收方分别对参数做MD5编码,一旦不一致便判断请求被篡改从而拒绝该请求,从而保证信息安全,编码后的字符串是编码前文本的一个简要梗概,因此它也被称作是信息摘要算法 这个算法的特点就是不可逆,只用于信息准确性和防篡改的校验,当然,MD5作为老牌的散列算法,很多经典的编码已经可以被反向解码出来(依靠正向的暴力穷举)以及被碰撞模仿(王小云院士团队的"破解"能够根据MD5编码后串码模拟原始消息,即使它可能与原信息不同),类似的还有SHA1,因此衍生了SHA224、SHA256、SHA512等更多安全的散列算法

2021-05-14鱼鱼
网络时延、异步IO、Pipeline
网络时延、异步IO、Pipeline通过使用多线程是能提高网络延迟带来的负面效应的,也就是在IO密集型的应用中(尤其是网络IO密集应用中),通过异步操作或能显著提高性能,本篇讨论相关问题 并不是异步(多线程)定能提高性能,有这种讨论也是发现经常有人会滥用多线程 通常会有一种说法:如果想要采用多线程的来执行一段任务,为了提高性能,假设服务器中有N个核心,推荐在CPU密集型的应用中启用N个线程,而在IO密集型的任务中启用2*N个线程 本人不是很认同此种说法,他只能代表一个大致的度量,在实际应用中几乎可以说完全不准确,一般来说,权衡系统资源与性能后,前者可能需要更少的线程数,而后者根据实际情况也许适宜分配更多的线程数 这个概念大家一般都不是很陌生,在此再次科普下:所谓IO密集型任务,即是任务的资源消耗多集中在系统IO上,这里的IO本来包括磁盘IO和网络IO等,但是磁盘IO涉及文件句柄操作等系统限制不在本篇讨论,所以此篇文章所提主要指网络IO,高网络IO也是绝大多数web应用的特性
2021-04-21鱼鱼
JVM的垃圾回收
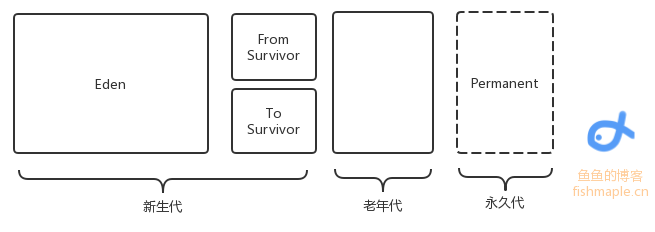
JVM的垃圾回收此文介绍Java的基本垃圾回收机制 GC主要回收的是堆区,在堆中是有对象分代的,一个对象每“逃”过一次回收,对象代数便+1,新生对象被称作新生代(如果是占据内存较大的对象直接定义为老年代),当代数一定时对象将由新生代变为老年代 同时在Java1.7之前还有永久代,保存了一些静态变量 总之,内存回收只发生在新生代和老年代之间 除了分代,内存也有分区: 如图,是内存区域分配,其中Eden存储了新建的小对象,当回收时,将Eden中存活的对象转移到To Survivor区中,将From Survivor中的代数高(一般是15)的存活对象转移到老年代中,代数没达到阈值的存活对象转移到To Survivor中
2021-04-07鱼鱼
分布式系统中的一致性算法和问题解决
分布式系统中的一致性算法和问题解决在撰写脑裂问题相关的博客时发现脑裂问题的产生原因在不同算法下的分布式系统各不相同,需要先大致了解一致性算法并针对性的解决 市面上有很多开源的分布式系统,他们的数据一致性算法不尽相同,例如k-v系统的祖师爷——zookeeper采用的是ZAB的算法,而最近流行的Consul是raft算法,不同数据中心server沟通的方式则是gossip协议 不同的协议和方式对选举和数据同步有不同的处理机制,利用这篇文章来对比常见的分布式一致性算法 一个系统可能会使用多个不同的一致性算法,以便于在不同的业务环节上有着各自更贴切的处理 ps:有种观点是一致性算法不是很准确,因为replica也能保证数据某种程度上具有一致性,有人称之为共识算法
2021-03-13鱼鱼
分布式系统一致性的分类
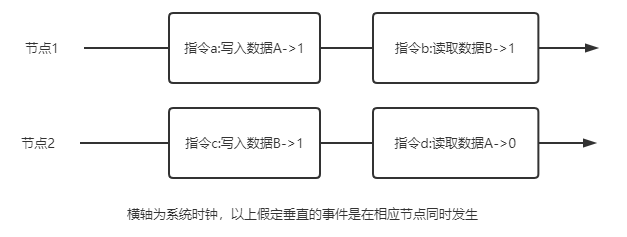
分布式系统一致性的分类在分布式系统中的CAP理论中有C(一致性),大郅表示分布式系统中节点状态或数据具有一致的特性 但一致性有着不同的分类,例如常见的用于取代CAP理论的BASE中的E,最终一致性,不同于强一致性,他强调着事务最终状态趋于一致,但中间态可能不一致,利用此篇文章总结一下分布式系统的一致性分类 根据实际系统的要求,分布式系统的一致性可以大致分为四类: 严格一致性 强一致性(线性一致/原子一致) 顺序一致性 弱一致性(最终一致性) 一个理想概念上的一致性,节点间数据完全一致,对外可表现为单个节点 由于网络延迟和通信等因素的存在,现实中这种一致性不可能存在 强一致性要求在全局时钟相同的条件下,对任何节点的读都相同且等于最后一次写成功的数据,这也就意味着仅仅在所有节点同步到数据后才会被标记为同步成功
2021-03-13鱼鱼
