Spring源码解析(3) IoC容器配置读取和容器refresh
Spring源码解析(3) IoC容器配置读取和容器refresh在文章Spring源码解析(I) 基于SSM看Spring的使用和Spring启动监听中,讲述了web容器启动后会触发的方法实现中生成Context的部分,回顾下核心方法: 我们已经分析到了0.处,他对我们生成的容器做了一个判断,对于web.xml监听初始化的Context,其生成的WebApplicationContext都是ConfigurableWebApplicationContext的子类,所以必然会进入if分支 首先通过loadParentContext先加载了父容器,默认是null 然后调用了configureAndRefreshWebApplicationContext方法进行初始化和配置项的读取

2020-08-09鱼鱼
Spring源码解析(1) 基于SSM看Spring的使用和Spring启动监听
Spring源码解析(1) 基于SSM看Spring的使用和Spring启动监听查看源码的顺序就见仁见智了,比较普遍的做法是从IoC入手,了解容器注入的每一个环节,掌握大致的流程 由于使用的是Spring,所以在这里我们引入比较古老的xml配置文件进行bean的配置,首先定义一个bean: 配置描述bean的xml,核心只有一行: 这样一来就可以使用BeanFactory这个容器来注入bean并使用了: 本来有封装好的XmlBeanFactory,这一类现在已经被弃用了,所以采用了他的父类DefaultListableBeanFactory;当然,也可以使用更加方便和常用的ApplicationContext: 当然从xml文件读取bean的配置只是其中一种目前用的不多的加载方式,还有基于包扫描等加载bean的方法,此处仅为理解IoC的基本使用
2020-08-04鱼鱼
阻塞队列与Protobuf的Udp通信 - 基于Cat的代理(Agent)项目拆解
阻塞队列与Protobuf的Udp通信 - 基于Cat的代理(Agent)项目拆解CAT是美团点评的一个基于Java开发的异常和性能监控项目,github地址:https://github.com/dianping/cat 本篇文章不是对CAT本身的源码拆解,而是基于本人依赖CAT client开发的代理项目进行拆解,但是并不会纰漏任何技术细节 CAT当前已有很多不同语言的Client,当然暂且是不 CAT本身是通过CAT client收集数据并上报至CAT server,server会进行并,共有六种常见数据格式:Transaction、Event、Problem、Metric、HeartBeat、调用链标记,其实如果不考虑复杂的处理(譬如Metric是可以基于指标生成折线图,Problem可以根据具体的异常类型追溯到相应的会话Track)除去Transaction剩余的数据格式都可以理解为特殊的Event

2020-07-19鱼鱼
算法:深度优先搜索(DFS)
算法:深度优先搜索(DFS)在算法:广度优先搜索(BFS)(最短路径)中,我们提到了按照广度优先遍历的搜索方式,使用队列作为常规的搜索方式,与之相对应的为深度优先搜索(DFS) 如果说BFS对应着树结构的前中后序遍历 但是DFS相对解法较为多元一些,有些时候不得不使用递归进行求解 同时,有很多求解只是进行图的遍历,不关心是广度还是深度优先,其解都是相同的 在这里我们暂且不讨论的基于栈而是侧重基于递归的遍历实现 对于二叉树,最常见的遍历方式有前序(又称 先序)遍历、中序遍历、后序遍历、层次遍历 前中后序只为取得的值先后顺序不同,即递归有先后 依赖栈实现的的深度优先是前序遍历 以下是一个二叉树的前序遍历代码实现:
![算法:深度优先搜索(DFS)]()
2020-06-27鱼鱼
算法:递归
算法:递归递归算法主要寻找: 终止条件:递归的尽头 单级递归的行为:在一次递归里要做的事情 返回值:每次迭代要return的东西 例如 首先,假定方法是已经实现的 终止条件为:当当前节点(传了空节点)或下一节点(传了单节点)为空,则无需反转返回当前节点 递归行为:假定之后的节点均已实现反转,则需要将已经反转的尾部的next变为当前节点,而当前节点由于是第一个节点,其next为null 此处注意在反转前需要先留存反转后的尾部; 返回值:返回反转后的头结点
![算法:递归]()
2020-06-24鱼鱼
Redis高级特性:事务和pipelined以及在RedisTemplate中的应用
Redis高级特性:事务和pipelined以及在RedisTemplate中的应用Redis Pipelined是由Client提供的(是防止client端 阻塞的操作)一种请求redis的方式 Redis本身具有很高的吞吐量,因此性能最大的考察便是网络状况,如果应用到redis的网络状况不好,每次请求都将会出现轻微的 阻塞和延迟,这种延迟对于批量请求是很可怕的,譬如要进行数千次数据插入,或是批量获取数据时,我们就需要用到Pipelined Pipelined可以将多个请求无 阻塞的发出并按顺序将请求结果“打包”返回,这有点类似于并发请求,可以有效地利用等待结果的 阻塞时间 注意,Pipelined并不能保证原子性,即pipelined执行的内容可能会被其他客户端或是线程的指令"插队",若想要原子性操作,需要使用事务
![Redis高级特性:事务和pipelined以及在RedisTemplate中的应用]()
2020-06-21鱼鱼
算法:广度优先搜索(BFS)(最短路径)
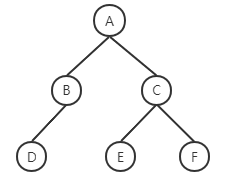
算法:广度优先搜索(BFS)(最短路径)我们先看一个案例: 遍历一个树结构,按层次输出树的节点内容,即:欲求 A B C D E F 实现方式便是从根节点(A)向下遍历,先获取A,其次是A的子节点B和C,其次是B的子节点D…… 这种遍历树结构或者图结构的方法被称作广度优先搜索(BFS),与之对应的先遍历到最下层子节点的是深度优先 BFS核心采用队列的数据结构,例如上面的树结构中,解法为: A进队列->A出队列 B、C进队列->B出队列 D进队列 ->C出队列 E、F进队列-> D、E、F出队列 如果想要区分层次边缘,使用count参数即可 解法步骤(蓝色部分为已经处理完的节点):
2020-06-05鱼鱼
