Redis原理-源码解析:数据结构1 字符串操作&SDS及预分配的实现验证
Redis原理-源码解析:数据结构1 字符串操作&SDS及预分配的实现验证所有原理实现基于Redis版本6.0.9 SDS(Simple Dynamic String)简单动态字符串,是Redis中字符串所采取的数据结构,SDS并不是Redis的独创,只是被Redis采纳的一种数据结构,用以替换C语言原生的字符串类型:sds仓库传送门 使用方法与原生的C语言字符串类似,并能提供很多类似的API SDS经过了两个版本,目前的解析大都基于v1 v1版本的sds数据结构很简单: 比起C语言中单一的字符数组构成的字符串,sds具有以下优势: 存储了字符串长度,相比C语言遍历获取长度,将时间复杂度由O(n)变为O(1); 当SDS每次发生修改时,会为其分配冗余空间,在字符串空间小于1MB时,每次分配实际长度2倍的空间,而在大于1MB时则是分配多1MB的空间,是在空间不足时才会触发分配

2020-11-16鱼鱼
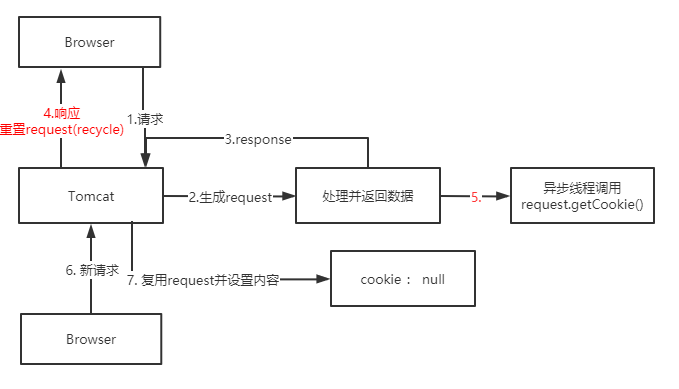
排坑指南-异步操作HttpServletRequest丢失Cookie
排坑指南-异步操作HttpServletRequest丢失Cookie遇到了一个很奇怪的bug:请求鉴权失败,因为通过Request对象获取到的Cookie中没有数据 经过debug调用request.getCookies()方法返回了null值,但是header属性的cookie却能拿到用户的有效cookie(request.getHeader("cookie")),其中缘由,且慢慢道来 我们可以在web项目中通过Request对象很方便的获取Cookie对象: 但其内部实现其实有一层缓存逻辑,从名为"cookie"的请求头中读取并处理数据转为Cookie对象并不是个省时事,在org.apache.catalina.connector.Request类中可以看到如下代码实现:
2020-11-11鱼鱼
浅谈代理-动态代理
浅谈代理-动态代理我们可以很轻松的实现一个简单的代理 实现静态代理是个很简单的事情,最基础的代理只需要定义一个接口(虽然不是必要,但这显然才是标准的设计)、一个被代理类和一个代理类,例如: 定义一个接口: 一个实现类: 和一个代理类: 实际使用时,我们是去调用HelloWorldProxy的方法,其将作为HelloWorld的代理实现 此种方式直接实现的代理太过于死板,因为每一种代理行为都要制定一个代理类,我们熟知的很多基于代理的实现(譬如AOP、事务)显然不可能用静态代理的方式针对每一处类切点都覆写一个代理类,这种时候就需要动态代理 我们所熟知的相当多的框架均基于动态代理开发,JDK本身基于反射(java.lang.reflect)提供了动态代理,我们只需定义代理的行为,而对于代理类的范围并不是固定值
![浅谈代理-动态代理]()
2020-10-13鱼鱼
ES快速入门(2)——Tokenizer、Reindex
ES快速入门(2)——Tokenizer、Reindex本篇介绍es提供的几种分词分析器和常用的开源分词分析器 es默认的分词器,中规中矩的按照 Unicode Standard Annex #29分词,一般的小写符号会忽略,对于中文等字符会逐字分割,参数max_token_length表示最大的字符长度,再切分后会继续按此切分 譬如: 会分词为: 一个无视语义,按照字符尽量收集全索引的分词方式,会前后叠加的按符号位分词,参数: 会分词为: nGram的分词很全面,但如此夸张的方式用不好会导致索引doc过大,同时使查询效率偏低 分词规则很简单,无其余规则的按空格分词: 会分词为: 在standard的基础上能够有效拆分出邮箱和url地址的格式,同样有max_token_length这一参数:
![ES快速入门(2)——Tokenizer、Reindex]()
2020-09-05鱼鱼
ES快速入门(I)——分析分词器
ES快速入门(I)——分析分词器本文旨在快速入门Elasticsearch的分词,包括分词分析器的创建和介绍对比等,请确保在阅读前已经搭建好完备的集群 文章基于es7.0+,与稍旧版本的主要区别是没有type 在讨论分词前,我们先看一下es整体创建倒排的分词过程: 我们常说的分词器指的其实是“分析器”analyzer,es将以上常用的逻辑封装起来成为analyzer,但是语义上的分词器是指上面的tokenizer 经过了三层处理后拿到了terms数组建立最终的倒排索引: character filter:一般不会用到这个filter,是在分词前对原有的文档字段内容做转换,例如去除html的标签提取出正文内容,按正则清除和替换某些内容,你可以指定及自定义0个到多个character filter,他们将共同存在,一个文本流在经过character filter处理后,依然是文本流;
![ES快速入门(I)——分析分词器]()
2020-09-01鱼鱼
JVM源码解析(2) ContextClassLoader与ClassUtil.forName()方法浅析
JVM源码解析(2) ContextClassLoader与ClassUtil.forName()方法浅析在Spring获取Context的源代码中,我们看到了对ClassUtil的方法调用,通过给定ClassName和ClassLoader进行Class的加载: ClassUtil.forName是仅供于Spring内部使用的获取Class对象的方法,来看一下源码: 首先 对于缓存的Class一块,在类的静态块中就能看出其逻辑: 在上面的resolvePrimitiveClassName方法中,先对长度做了一个判断,因为较长的packagename会影响执行的性能: 最终加载Class依旧是通过ClassLoader的,先来看一下获取ClassLoader的方法实现: 此处优先使用了ContextClassLoader作为 类加载器而非默认的AppClassLoader,在JVM源码解析 从 Launcher类浅谈ClassLoader中,提到了关于 类加载器的相关知识,使用ContextClassLoader是为了弥补双亲委派加载机制的对于自定义 类加载器的缺憾:那些自定义的 类加载器并没有机会上场,在使用了AppClassLoader后我们的自定义ClassLoader所加载的Class是无法被加载进去的,使用ContextClassLoader,我们可以在定义线程时,通过Thread的init方法(子线程调用,私有方法)或是setContextClassLoader直接指定使用自定义的ClassLoader
![JVM源码解析(2) ContextClassLoader与ClassUtil.forName()方法浅析]()
2020-08-16鱼鱼
IO多路复用模型:select、poll、epoll对比
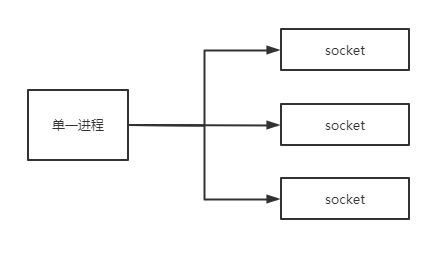
IO多路复用模型:select、poll、epoll对比我们平时提到的I/O几乎都是同步 阻塞模型,譬如网络请求的socket IO,在数据返回前,相应的线程或是进程将会一直 阻塞直到数据返回,比较直接的处理便是针对IO流一对一的监听,但在IO返回前,相应的系统资源会平白无故的浪费,这种处理方式会大大降低服务器的吞吐 如果我们用很少的线程来监听这些IO,就能实现对系统资源的更好利用,在相应的socket有数据返回时才去读取数据 这种方式被称作IO多路复用,在Linux系统中,实现IO多路复用的方式(从古老到新)有select、poll和epoll 现在很多中间件都使用epoll IO多路复用模型才因此有着很高的性能和吞吐 此处简单描述三种方式的实现和区别
2020-08-11鱼鱼
