MySQL tips
MySQL tips一些日常接触到的MySQL优化tips,比较散乱 假设有一个用户表,对于一句很简单的查询语句: 假设name与age字段均有单列索引,容易想到的是,MySQL应该会分别走两次索引,并将其结合起来,EXPLAIN也是如此,大多数时候MySQL会进行优化,我们可能会看到EXPLAIN的结果中有Using union或Using soft union,这是MySQL针对OR做了隐性的优化,但当SQL复杂或数据极端情况下,这一语句极容易变成全表扫描,偶尔使用联合索引可能解决问题,更多情况则是MySQL“昏了头”,即使OR条件均涉及数据条数不多,依旧没能在查询语句中使用索引,此时应调整为UNION语句(可以权衡一下重复及顺序是否有影响,可以使用更快的UNION ALL):

2021-01-13鱼鱼
使用RPC与Restful接口调用服务
使用RPC与Restful接口调用服务在SOA和微服务架构中,远程通信是无法避免的,最常用的远程通信有两种方式: restful的接口,使用Http通信 使用dubbo或是Spring Cloud组件进行 RPC协议远程调用,可选地使用socket通信 不同的人对 RPC调用会有不同的看法,甚至对rpc本身的理解都不甚相同,但我认为 RPC有两种倾向: 一为语义化的 RPC 没有统一的请求规范,数据格式在开发人员中很难达成一致,在使用传统Http调用时,交互的双方需要约定一份“API文档”以保证数据格式的唯一性,这样API格式本身就成为了一道大墙,耽误研发双方的时间 但如果服务间采用语义化 RPC进行交互,双方可能并不需要一份文档,只要一份约定好的代码,并以此作为双方的依赖,在请求时也仅仅是直接调用方法本身,如此强的语义性怎能让人不爱
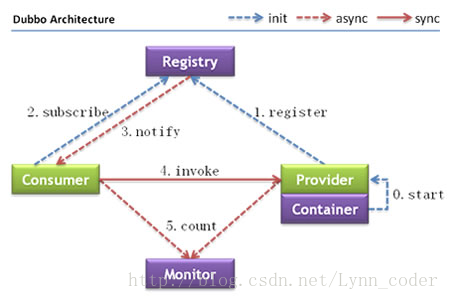
2021-01-13鱼鱼
动态路由数据源(多租户)解决方案
动态路由数据源(多租户)解决方案当下有很多服务都使用了多数据源,或是出于跨库查询或是分库分表、读写分离等,多数据源解决方案早已不是稀罕事 常见的解决方案包括使用多数据源框架(例如Shareding-Jdbc)、在数据库端做代理(例如MYCAT)、对于固定的几个数据源连接,也可以直接手动配置多个数据源,这种相关处理有很多源码,我在github上也有简单的实现:fishstormX/dynamicDataSource: 动态数据源的实现,基于maven自定义多模块骨架 Spring Boot2.0.x,本文实现的是动态数据源,主要为了解决 多租户问题(不同的用户群组有不同的数据源和配置,强调数据的隔离性) 本文技术能实现的是动态数据源,基于Spring框架,即能够将注入的Datasource根据租户不同使用不同的来源,同时根据租户增减动态的增删和缓存数据源(增是因为会有新增租户可能使用到项目启动后的数据源,减是因为租户数不可预料,不可直接缓存所有的数据源)
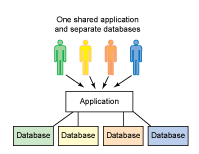
2021-01-07鱼鱼
Redis原理-源码解析:数据结构3 hash
Redis原理-源码解析:数据结构3 hash 所有原理实现基于Redis版本6.0.9 hash在Redis中可以认为是套了一层的string,当然,对hash来说没有数字类型 让我们依旧通过基本命令看看hash的基本数据结构实现 在set方法中我们看到了hash的初始创建过程,一个hash最开始是zipist 想要了解ziplist可以看Redis原理-源码解析:数据结构2 list ,是为节省内存而生的链表格式 所以其实在使用ziplist时其查询的时间复杂度不是遵循hash的近似O(1),而是O(n),但是在数据量不大时,这种性能的损失微乎其微,并且能预见到大多数使用hash的场景都不会存储过多的字段 所以优先使用了更节省内存空间的ziplist

2020-11-29鱼鱼
Java排坑指南(I)jmap jstack jstat等的使用
Java排坑指南(I)jmap jstack jstat等的使用运用一些Java自带的可执行jar可以从内存的角度更轻松的排除项目中的问题,我们可能会遇到一些不常见却相对很致命的问题,例如: 某些web项目CPU跑到了100%并且飙高不下(一般来说,web应用都为IO密集应用,不太可能出现cpu高占用的情况) 项目中线程出现阻滞、阻塞(网络请求响应速度明显变慢,甚至因为死锁彻底出现阻塞等) 极可能由内存泄漏引发的不明原因的 OOM(没有预兆的或是基础逻辑问题的内存溢出) 当以上问题发生时,通过代码或是日志其实很难定位到原因所在,因为这一般是基于环境或资源导致的全局性问题,通常很难定位,这时可以通过使用Java自带的性能调优jar包更便捷的定位问题(如果没有配置环境变量,可以在jdk的bin目录下找到他们的jar包)
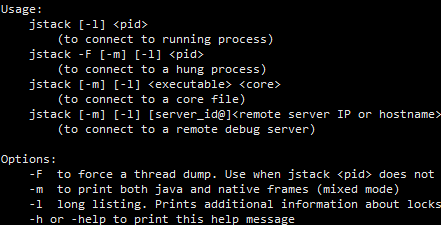
2020-11-28鱼鱼
JVM源码解析 从Launcher类浅谈ClassLoader(类加载器及双亲委派)
JVM源码解析 从Launcher类浅谈ClassLoader(类加载器及双亲委派)首先普及ClassLoader的基础:所有的Java类都是由ClassLoader由class文件加载进内存的,对于一个类,其唯一标识就是类名+加载他的ClassLoader(亦即对于不同的 ClassLoader,即使是加载了同一个Class也不能互通,本质上是两个类),其基本的分类如下图: BootstrapClassLoader是一个特殊的ClassLoader,负责启动时加载jre的类库 并不继承于ClassLoader,因为是jvm逻辑的一部分; ExtClassLoader也会加载jre类库,但是会加载那些额外的扩展类库(jre\lib\ext目录),到这个级别的 类加载器已经可以直接在代码中使用了;
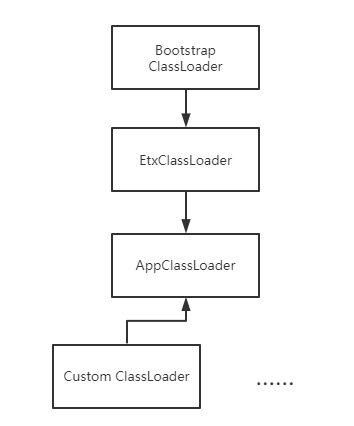
2020-11-28鱼鱼
Redis原理-源码解析:数据结构2 list
Redis原理-源码解析:数据结构2 list所有原理实现基于Redis版本6.0.9 Redis中的list采用的是链表,在开始前,我们先看看list的最基本指令实现 t-list.c 由此可知,Redis的List底层数据结构都是基于quickList的 这是list所依赖的数据结构: quicklist.h 我们注意到其是由quicklistNode所构成的链表,而其中的数据实则为zl(ziplist)或是bookmark,在大多时候quicklistNode都使用ziplist存储数据 在上文中lpush执行了一个插入方法quicklistPush,在quicklist.c中有他的实现: quicklist真正存储数据的结构是ziplist,所以倒不如说,在Redis中,list是一个由ziplist节点构成的链表
2020-11-28鱼鱼
