AI大模型定价对比
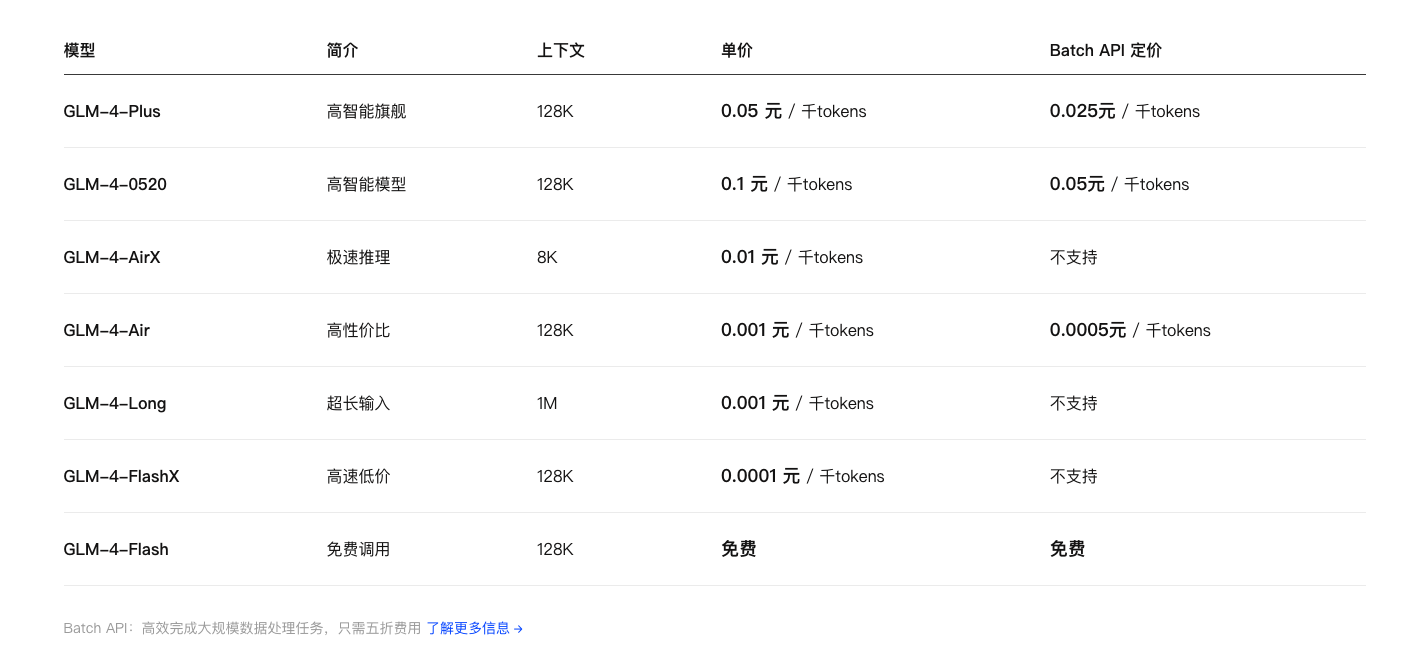
AI大模型定价对比https://open.bigmodel.cn/pricing 火山方舟也提供端点(GLM3 0.001) https://openai.com/ja-JP/api/pricing/ 出入价格不一样 官网和火山都有 另外有免费版本的
2024-12-18鱼鱼
Java中的协程(虚拟线程)探究
Java中的协程(虚拟线程)探究在Java最新的LTS版本 21中,终于实装了协程这一特性 当然,在这些诸如python、golang等轻量级语言中被称为协程的东西,在Java中有个全新的代号——虚拟线程,为了将协程与线程做区分,在Java21中,原Thread被称之为平台线程 下文中,将统一使用线程/协程的方式称呼 我们都知道,Java中引入了线程的概念,区别于系统中的进程 作为并发执行的最小单元,在一定的条件下,使用多个线程同时运作可以有效提高程序的运转效率 而线程这一能力源于系统本身而并非JVM 之所以说是在一定条件下,是因为受限于机器配置情况(CPU的运作机制、核心数),线程的同时运作并不能线性的提升运行性能,单个cpu并不能同时处理多线程任务,实际的运作方式是基于时间片分片,各个线程抢占式执行代码,这样能减少一些无效的io等待(例如网络io、磁盘io实际是会阻塞等待io结果),同时在多核心场景下也能有效利用cpu
![Java中的协程(虚拟线程)探究]()
2024-10-28鱼鱼
浅谈锁机制、主流锁设计方案
浅谈锁机制、主流锁设计方案本文旨在探讨通用的锁机制实现逻辑,以Java中常见的锁实现为例 本文提到的锁,是指通过限制并发/并行访问所添加的安全措施,本质上是通过限制线程/进程同时更改数据或是读取数据与写入数据产生时序差从而造成数据问题 锁机制中,有一些常见特性: 可重入性 指同一线程/进程携带相同的标识可以反复多次加锁,每次加锁和释放锁对应的重入次数+1/-1; 读写锁/独享共享 是锁的不同运作模式,分为读写锁,读锁与写锁、写锁与写锁是互斥的,但多个线程/进程可以同时对一个逻辑添加读锁,独享共享是另一种叫法 公平性 锁分为 公平锁和非 公平锁, 公平锁指锁释放和获取的顺序严格按照索取的顺序,非 公平锁则是等待锁的对象共同进行锁释放机会的争抢
![浅谈锁机制、主流锁设计方案]()
2024-10-15鱼鱼
Java的SPI机制
Java的SPI机制SPI(Service Provider Interface) 是JDK内部提供的一种用于服务能力扩展的机制 在服务中通过不同的下沉方法实现能够加载不同的接口实现类,从而实现功能的热插拔 相比一些类似的设计模式(例如策略模式), SPI作为Java自带的实现特性,相对更加灵活和开放 我们常见的JDBC、日志框架slf4j、JavaMail、Spring等组件都基于 SPI实现(例如JDBC针对不同数据源的驱动) 之所以说区别于Java的一些设计模式,因为Java有一些实现能实现 SPI的动态加载 首先让我们定义 SPI对外提供抽象能力的接口类,这里为了便于理解展示包路径:

2024-10-14鱼鱼
kasper的算法(从0到1)
kasper的算法(从0到1)https://javaguide.cn/cs-basics/data-structure/linear-data-structure.html https://javaguide.cn/cs-basics/algorithms/linkedlist-algorithm-problems.html 项目地址:https://github.com/labuladong/fucking-algorithm 在线文档地址:https://labuladong.gitee.io/algo/home/ http://fishmaple.cn/blog/topicBlog?topicId=7
![kasper的算法(从0到1)]()
2023-10-23kasper
Kafka服务端集群原理
Kafka服务端集群原理kafka是家喻户晓的消息队列,也因“纯粹”而闻名(高性能高吞吐、扩展较少较为简单),此篇文章整理Kafka的基本架构,将按照Kafka的版本迭代分别展示架构的演进(截至版本3.0) 我们在这里暂且只讨论Kafka服务端,对于生产者和消费者的逻辑简单带过 扫盲一下Kafka的部分概念: Producer mq生产者通用叫法 作为消息的生产者,在生产完消息后需要将消息投送到指定的目的地(某个topic的某个partition) Producer可以根据指定选择partition的算法或者是随机方式来选择发布消息到哪个partition; Consumer mq生产者通用叫法 消息消费者,向Kafka broker读取消息的客户端;,负责订阅和消费消息

2022-03-10鱼鱼
浅析RPC框架Thrift
浅析RPC框架ThriftThrift是由Facebook开发的 RPC远程调用的框架,使用独有的Thrift协议进行可跨语言的远程调用 有点类似protobuf 无论使用何种语言,首先要准备Thrift编译环境,可以去官网下载相应的Thrift执行文件,下文均以Windows为例 下载后可以选择性的配置环境变量,最终在shell中可执行Thrift 在项目中,预先准备好libthrift依赖,maven写法: 例如: 定义一个testService.thrift(idl文件名不重要),一般都会定义在resources的thrift文件夹下: 这里定义了两个方法,分别返回字符串和int类型,在thrift的idl中,对于变量的定义如下:
2022-03-04鱼鱼
